【哪吒开发板试用】基于哪吒开发套件开发LLM + RAG应用
关于哪吒开发板 哪吒(Nezha)开发套件以信用卡大小(85 x 56mm)的开发板-哪吒(Nezha)为核心,采用英特尔®处理器 N97(Alder Lake-N),结合了高性能和低功耗的特性。它支持四核 SoC,时钟频率高达 3.60GHz&
关于哪吒开发板
- 哪吒(Nezha)开发套件以信用卡大小(85 x 56mm)的开发板-哪吒(Nezha)为核心,采用英特尔®处理器 N97(Alder Lake-N),结合了高性能和低功耗的特性。它支持四核 SoC,时钟频率高达 3.60GHz,TDP 仅为 12W。 其内置 GPU 用于 高分辨率显示。哪吒保持了 85mm x 56mm 信用卡大小的外形尺寸,与树莓派相同,包括高达 8GB 的 LPDDR5 系统内存、高达 64GB 的 eMMC 存储、板载 TPM 2.0、40 针 GPIO 连接器,并支持 Windows 和 Linux 操作系统。这些功能与无风扇冷却器相结合,为各种应用构建了高效的解决方案,适用于教育、物联网网关、数字标牌和机器人等应用。
- 内置 Intel® UHD Graphics Gen12,最多 24 个执行单元,这也是一个强大的 AI 引擎,可用于 AI 推理。它是基于 Xe 架构的新一代 GPU。支持包括 INT8 在内的主要数据类型。通过HDMI 1.4b端口,它支持30Hz的4K UHD(3840×2160)以实现高分辨率显示。
- 40引脚HAT GPIO可配置为PWM、UART、I2C、I2S、SPI和ADC。它为开发人员提供了构建解决方案的自由。
- 出厂代理windows操作系统
不足的地方,没有自带蓝牙和WiFi模块,需要自己准备一个蓝牙接收器和无线网卡。如果你不需要这些功能就无所谓了。


前置准备
- 一个外置硬盘
- 无线网卡(可选)
- 键鼠(可选)
- HIDMI(可选)
开发环境设置
哪吒开发套件自带了windows11系统,我这里已经连好了局域网,我们通过远程桌面进行链接。
远程桌面需要额外设置,这里不赘述了。大家自行搜索一下即可。

我这里配置了一个外置SSD硬盘
1. 安装miniconda环境
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe -o miniconda.exe
start miniconda.exe
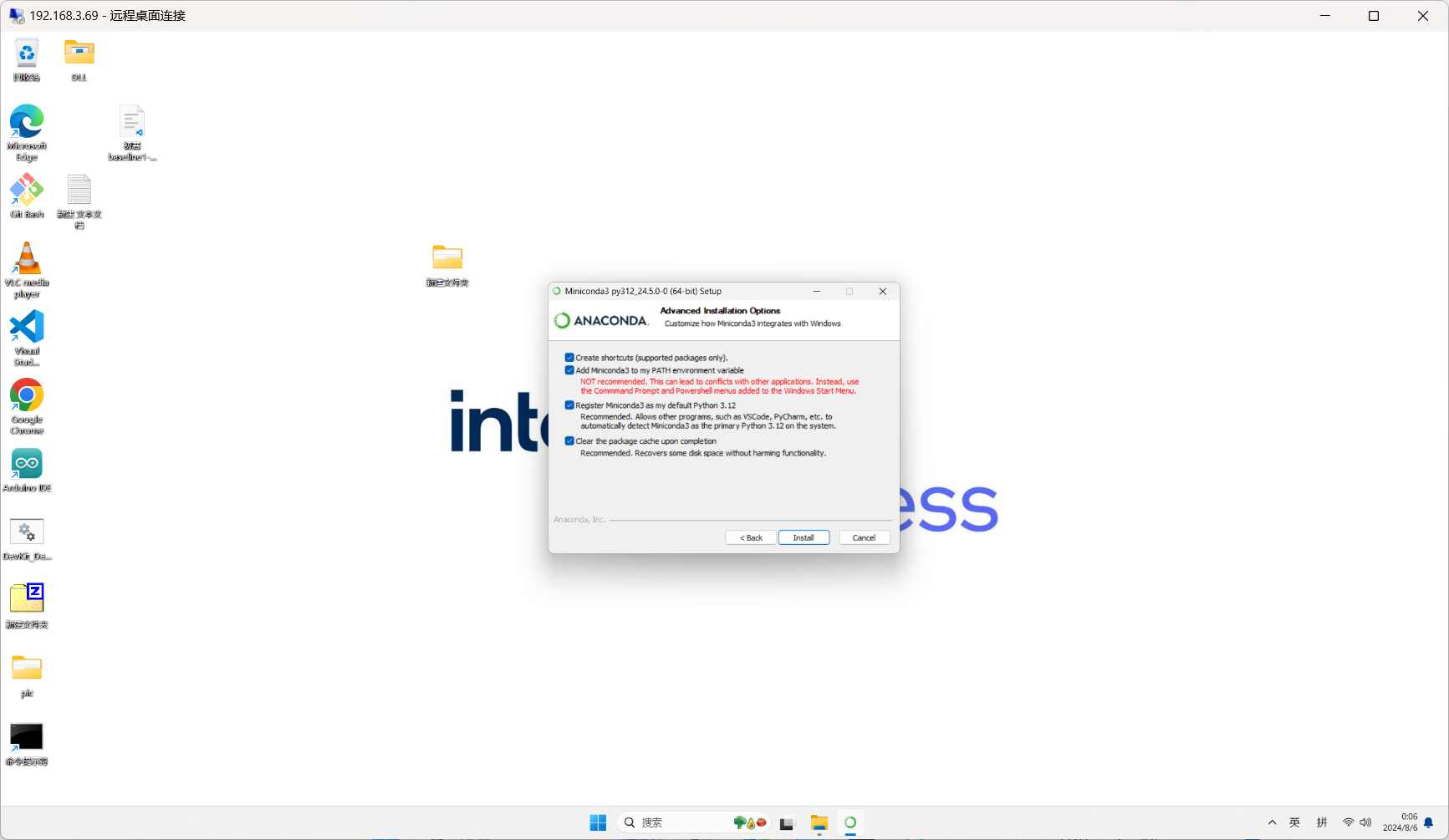
运行上面的命令启动exe进行安装,也可以双击打开进行安装。
其他界面直接下一步,除了下面的界面需要全部选择上。
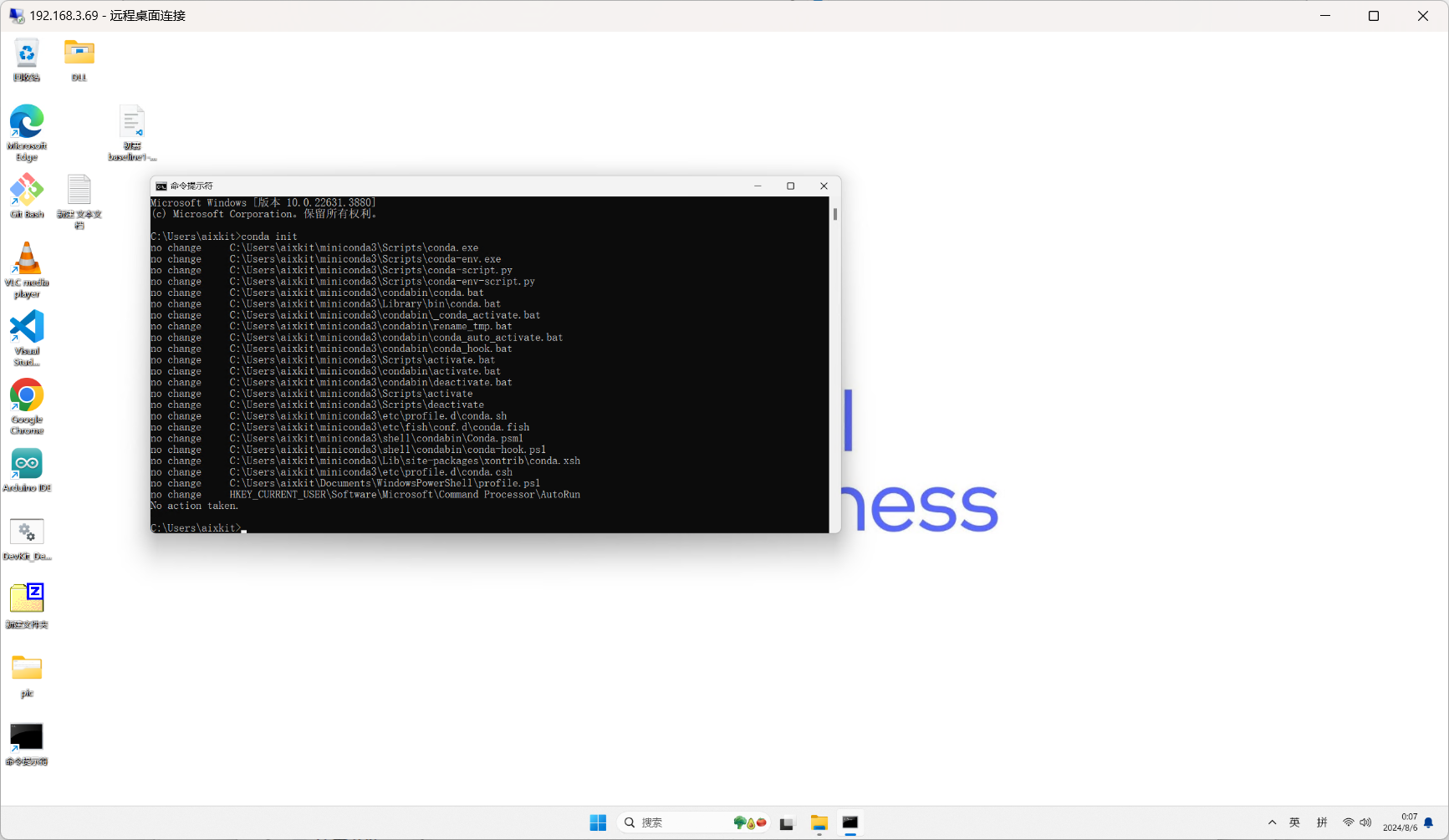
新开一个命令行窗口,运行以下命令初始化conda环境
conda init
2. 配置本次项目环境
本次项目主要使用Intel 的IPEX库进行实验。由于我们打大模型文件通常都很大,一次建议大家将conda的环境设置到一个外置的U盘中,包括后面下载的模型文件也放到这一个U盘上。
conda config --add envs_dirs D:\conda_envs
进入到我们的项目目录
创建虚拟环境
conda create -n ipex python=3.10 -y

激活虚拟环境
conda activate ipex
运行以下命令进行环境安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
文件内容如下
ipex-llm==2.1.0b20240711
py-cpuinfo
gradio
streamlit
modelscope==1.12.0
transformers==4.37.0
accelerate==0.27.2
jupyterlab
ipykernel
PyMuPDF
llama-index-vector-stores-chroma
llama-index-readers-file
llama-index-embeddings-huggingface
llama-index
为了能在jupyuterlab中看到我们的conda环境,我们运行以下命令将当前的环境添加到jupyterlab中
python -m ipykernel install --name=ipex
注意这里需要在虚拟环境下执行,即我们运行好
conda activate ipex后。
启动jupyterlab
python -m jupyterlab
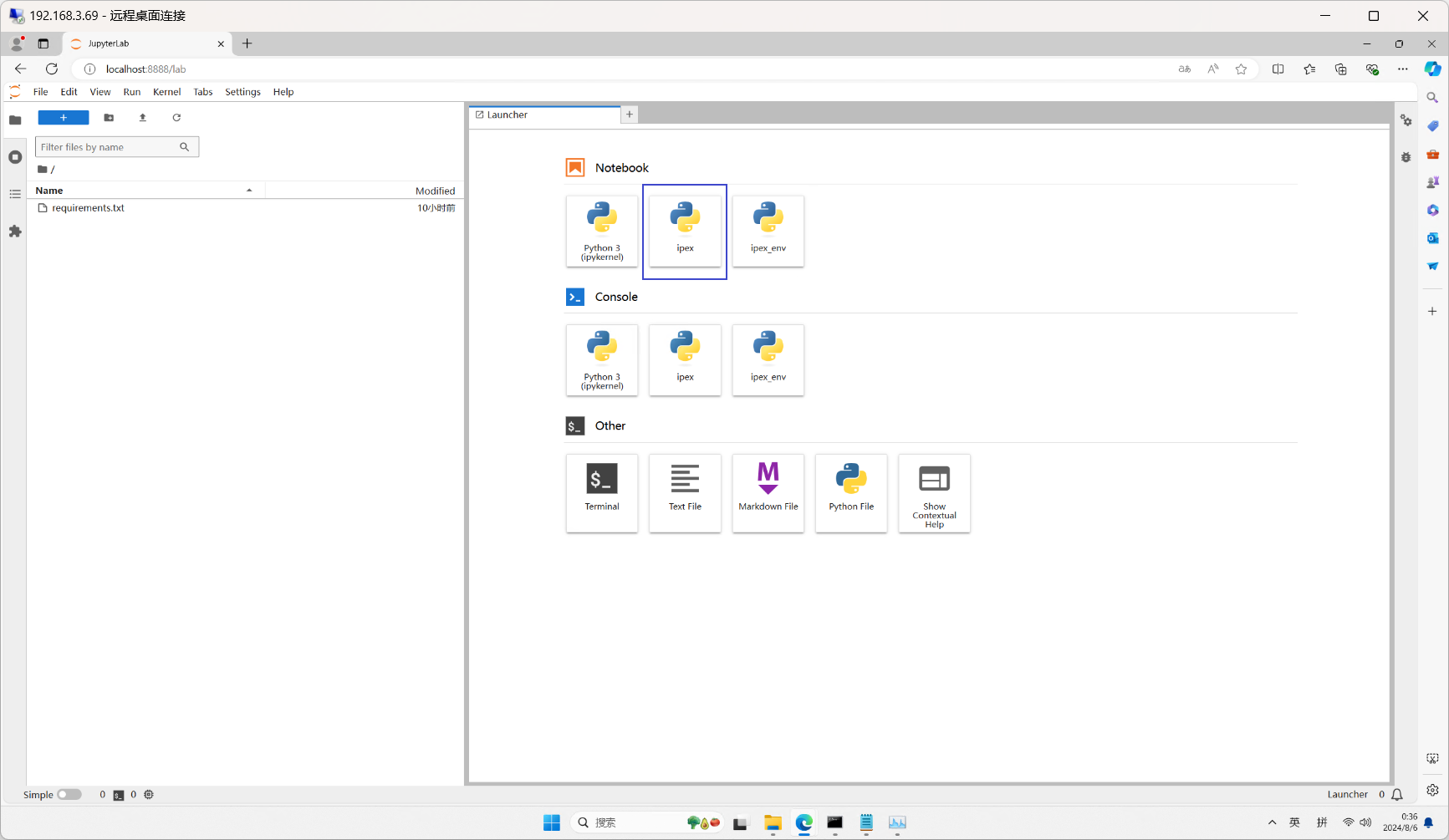
可以看到我们的环境已经添加到了notebook中。
开发LLM +RAG 代码
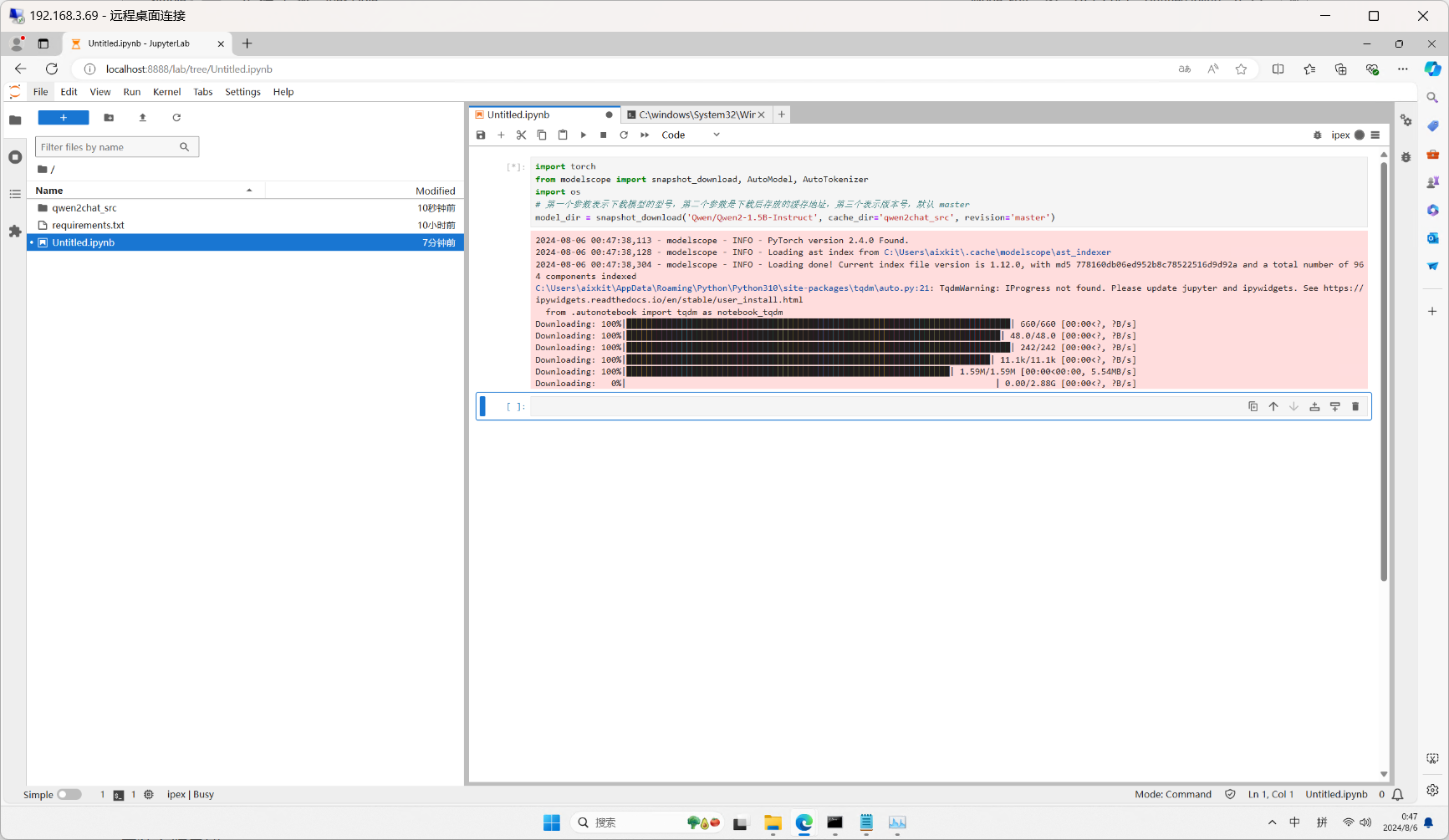
我们运行以下代码下载千问模型和权重文件
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
# 第一个参数表示下载模型的型号,第二个参数是下载后存放的缓存地址,第三个表示版本号,默认 master
model_dir = snapshot_download('Qwen/Qwen2-1.5B-Instruct', cache_dir='qwen2chat_src', revision='master')
如果你看到如下报错画面,需要通过conda重新安装一下pytorch
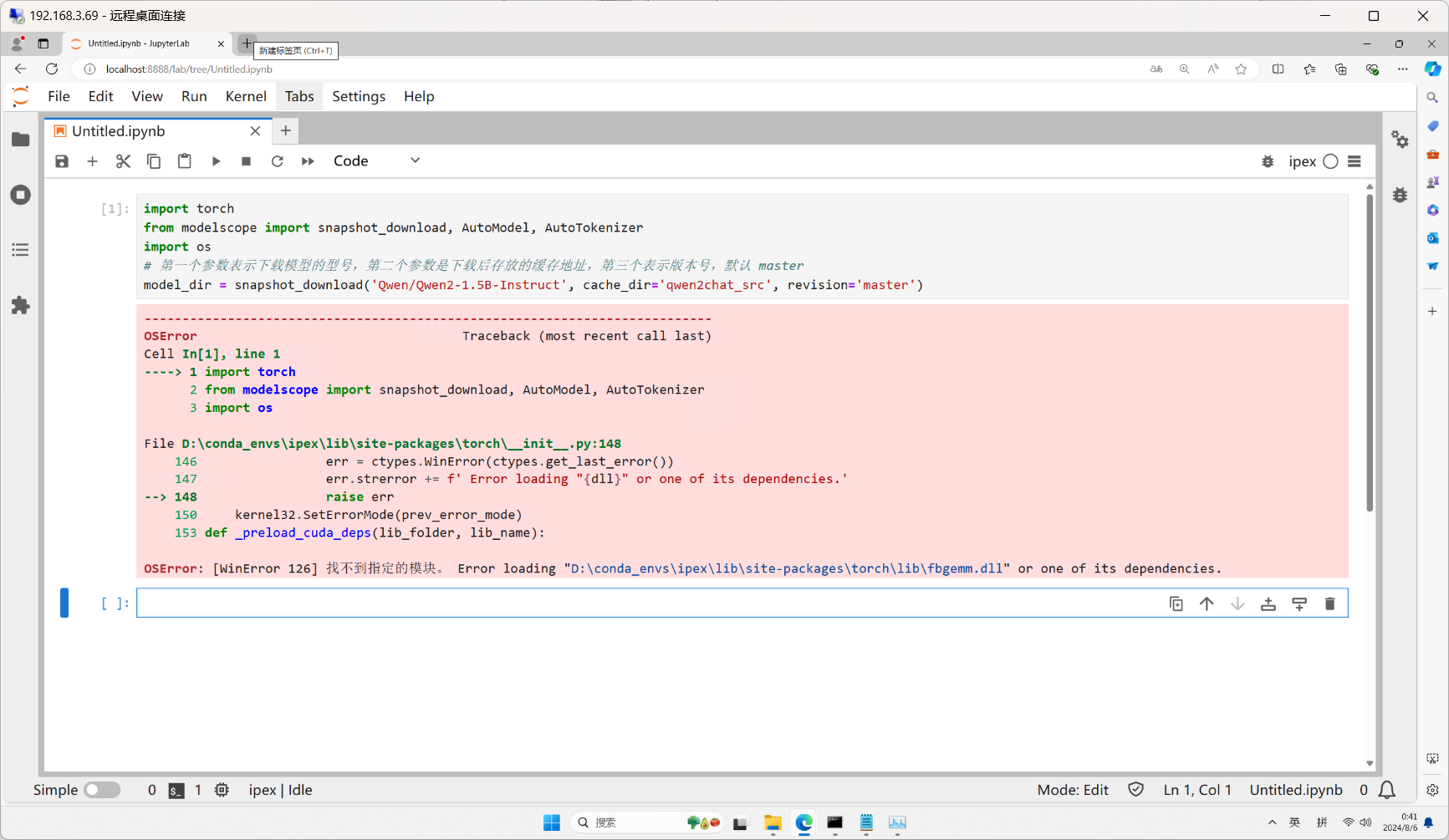
conda install pytorch torchvision torchaudio cpuonly -c pytorch
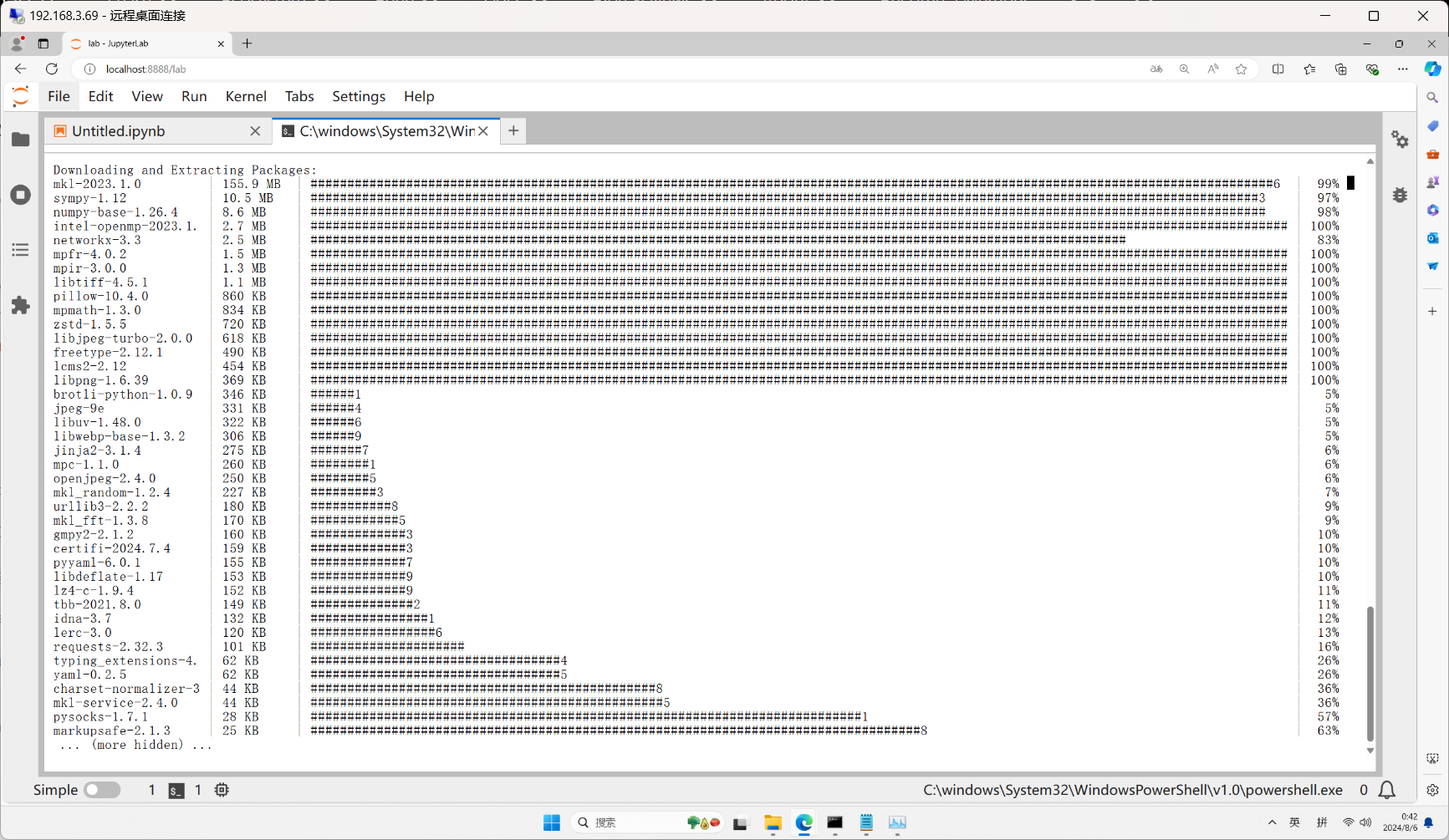
等待安装完成,重启一下kernel再次运行这个代码块可以看到模型有正常的的开始下载。
Int4量化
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
model_path = os.path.join(os.getcwd(),"qwen2chat_src/Qwen/Qwen2-1___5B-Instruct")
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_low_bit='sym_int4', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model.save_low_bit('qwen2chat_int4')
tokenizer.save_pretrained('qwen2chat_int4')
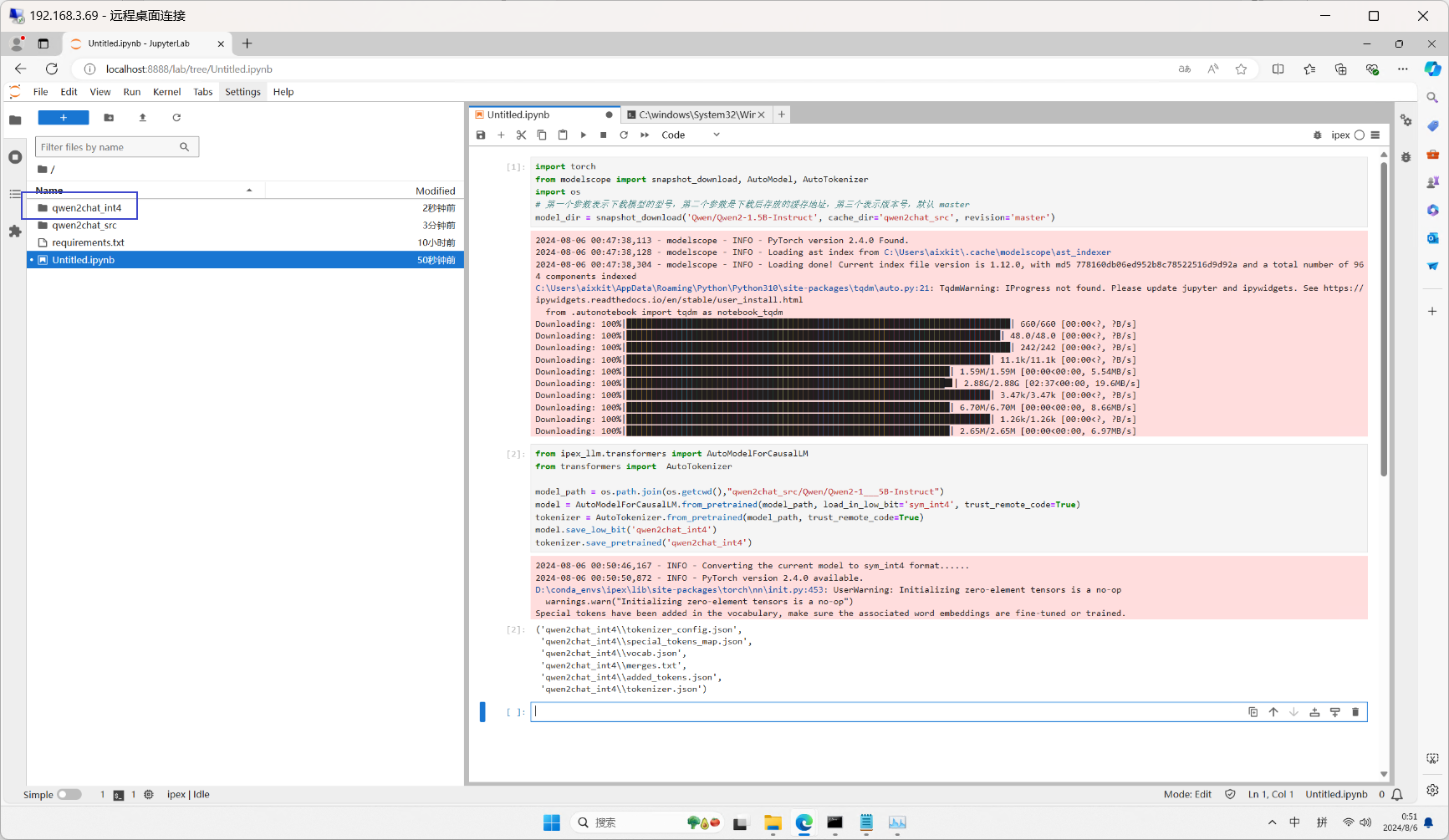
量化好之后,我们可以看到在根目录下创建了一个qwen2chat_int4的文件夹。
我们创建一个执行文件
%%writefile ./run_stream.py
# 设置OpenMP线程数为8
import os
os.environ["OMP_NUM_THREADS"] = "8"
import time
from transformers import AutoTokenizer
from transformers import TextStreamer
# 导入Intel扩展的Transformers模型
from ipex_llm.transformers import AutoModelForCausalLM
import torch
# 加载模型路径
load_path = "qwen2chat_int4"
# 加载4位量化的模型
model = AutoModelForCausalLM.load_low_bit(load_path, trust_remote_code=True)
# 加载对应的tokenizer
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True)
# 创建文本流式输出器
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# 设置提示词
prompt = "给我讲一个芯片制造的流程"
# 构建消息列表
messages = [{"role": "user", "content": prompt}]
# 使用推理模式
with torch.inference_mode():
# 应用聊天模板,添加生成提示
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 对输入文本进行编码
model_inputs = tokenizer([text], return_tensors="pt")
print("start generate")
st = time.time() # 记录开始时间
# 生成文本
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512, # 最大生成512个新token
streamer=streamer, # 使用流式输出
)
end = time.time() # 记录结束时间
# 打印推理时间
print(f'Inference time: {end-st} s')
创建好之后,我们可以运行以下命令
python ./run_stream.py
运行效果以及CPU和内存表现如下
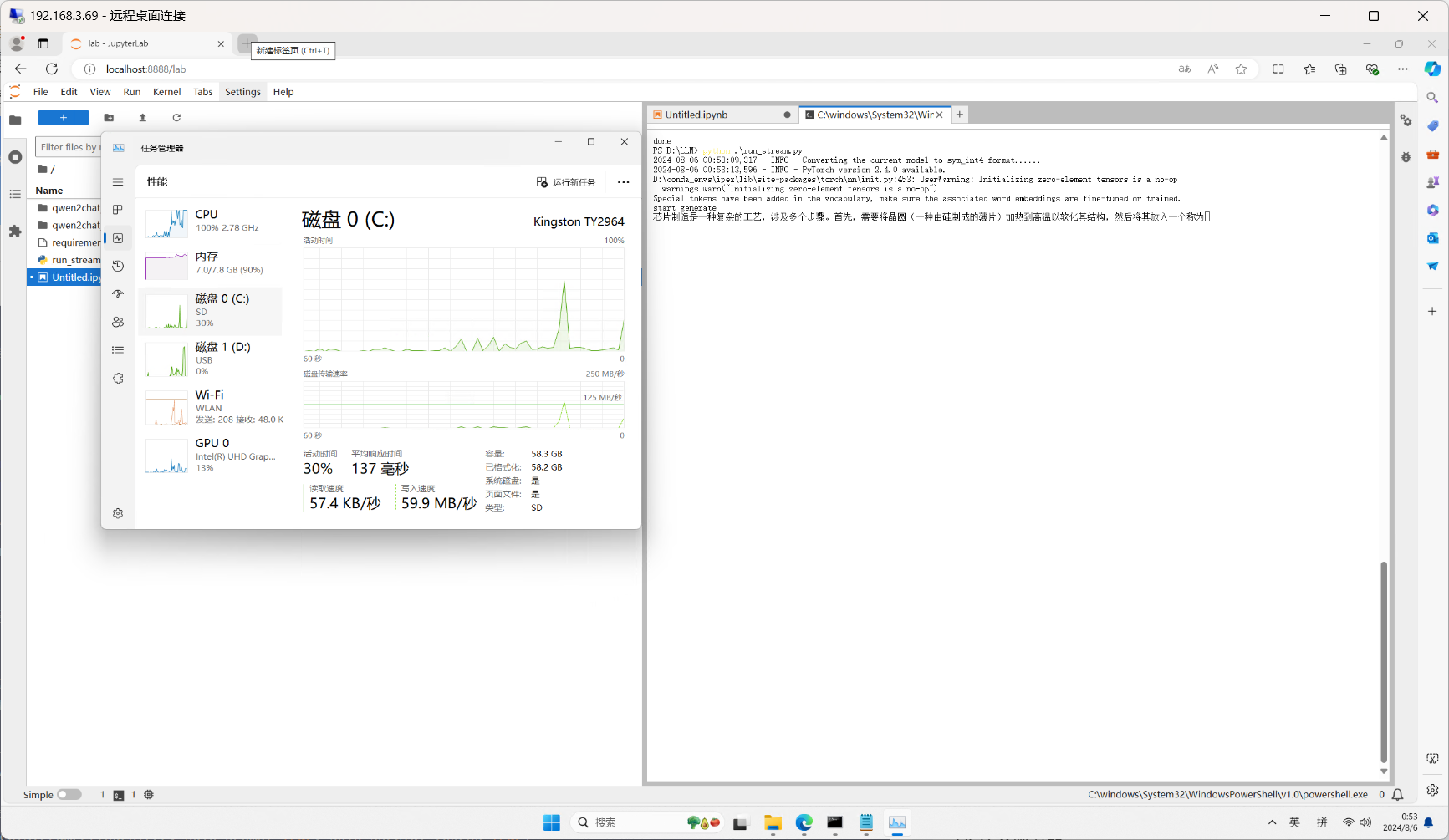
后面的代码这里就不一一说明了,将完整代码提供给大家
import os
import time
import gradio as gr
os.environ["OMP_NUM_THREADS"] = "8" # 设置OpenMP线程数为8
import gradio as gr
from PIL import Image
import torch
import requests
import io
from pathlib import Path
from typing import Any, List, Optional
from modelscope import snapshot_download, AutoModel, AutoTokenizer
# 从llama_index库导入HuggingFaceEmbedding类,用于将文本转换为向量表示
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 从llama_index库导入ChromaVectorStore类,用于高效存储和检索向量数据
from llama_index.vector_stores.chroma import ChromaVectorStore
# 从llama_index库导入PyMuPDFReader类,用于读取和解析PDF文件内容
from llama_index.readers.file import PyMuPDFReader
# 从llama_index库导入NodeWithScore和TextNode类
# NodeWithScore: 表示带有相关性分数的节点,用于排序检索结果
# TextNode: 表示文本块,是索引和检索的基本单位。节点存储文本内容及其元数据,便于构建知识图谱和语义搜索
from llama_index.core.schema import NodeWithScore, TextNode
# 从llama_index库导入RetrieverQueryEngine类,用于协调检索器和响应生成,执行端到端的问答过程
from llama_index.core.query_engine import RetrieverQueryEngine
# 从llama_index库导入QueryBundle类,用于封装查询相关的信息,如查询文本、过滤器等
from llama_index.core import QueryBundle
# 从llama_index库导入BaseRetriever类,这是所有检索器的基类,定义了检索接口
from llama_index.core.retrievers import BaseRetriever
# 从llama_index库导入SentenceSplitter类,用于将长文本分割成句子或语义完整的文本块,便于索引和检索
from llama_index.core.node_parser import SentenceSplitter
# 从llama_index库导入VectorStoreQuery类,用于构造向量存储的查询,支持语义相似度搜索
from llama_index.core.vector_stores import VectorStoreQuery
# 向量数据库
import chromadb
from ipex_llm.llamaindex.llms import IpexLLM
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
class VectorDBRetriever(BaseRetriever):
"""向量数据库检索器"""
def __init__(
self,
vector_store: ChromaVectorStore,
embed_model: Any,
query_mode: str = "default",
similarity_top_k: int = 2,
) -> None:
self._vector_store = vector_store
self._embed_model = embed_model
self._query_mode = query_mode
self._similarity_top_k = similarity_top_k
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""
检索相关文档
Args:
query_bundle (QueryBundle): 查询包
Returns:
List[NodeWithScore]: 检索到的文档节点及其相关性得分
"""
query_embedding = self._embed_model.get_query_embedding(
query_bundle.query_str
)
vector_store_query = VectorStoreQuery(
query_embedding=query_embedding,
similarity_top_k=self._similarity_top_k,
mode=self._query_mode,
)
query_result = self._vector_store.query(vector_store_query)
nodes_with_scores = []
for index, node in enumerate(query_result.nodes):
score: Optional[float] = None
if query_result.similarities is not None:
score = query_result.similarities[index]
nodes_with_scores.append(NodeWithScore(node=node, score=score))
print(f"Retrieved {len(nodes_with_scores)} nodes with scores")
return nodes_with_scores
class RuanKao:
def __init__(self) -> None:
self.text_example_cn = "https://github.com/openvinotoolkit/openvino_notebooks/files/15039713/Platform.Brief_Intel.vPro.with.Intel.Core.Ultra_Final_CH.pdf"
BASE_DIR = os.getcwd()
self.model_name = "qwen2chat_int4" #os.path.join(BASE_DIR,"qwen2chat_src", "Qwen", "Qwen2-1___5B-Instruct")
self.model_path = os.path.join(BASE_DIR,"qwen2chat_src/Qwen/Qwen2-1___5B-Instruct")
self.tokenizer_path = "qwen2chat_int4"
self.data_path = "./data/Platform.Brief_Intel.vPro.with.Intel.Core.Ultra_Final_CH.pdf"
self.embedding_model_path = "qwen2chat_src/AI-ModelScope/bge-small-zh-v1___5"
self.max_new_tokens = 64
self.persist_dir = "./chroma_db2"
self.question = ""
self.text_example_cn_path = Path(".data/text_example_cn.pdf")
# self.dl_model()
# if not self.text_example_cn_path.exists():
# r = requests.get(url=self.text_example_cn)
# content = io.BytesIO(r.content)
# with open("text_example_cn.pdf", "wb") as f:
# f.write(content.read())
def dl_model(self):
# Base
# 第一个参数表示下载模型的型号,第二个参数是下载后存放的缓存地址,第三个表示版本号,默认 master
snapshot_download('Qwen/Qwen2-1.5B-Instruct', cache_dir='qwen2chat_src', revision='master')
if not os.path.exists(os.path.join(os.getcwd(), "qwen2chat_int4")):
print(self.model_path)
# to int 4
# model_path = os.path.join(os.getcwd(),"qwen2chat_src/Qwen/Qwen2-1___5B-Instruct")
model = AutoModelForCausalLM.from_pretrained(self.model_path , load_in_low_bit='sym_int4', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(self.model_path , trust_remote_code=True)
model.save_low_bit('qwen2chat_int4')
tokenizer.save_pretrained('qwen2chat_int4')
# embedding
snapshot_download('AI-ModelScope/bge-small-zh-v1.5', cache_dir='qwen2chat_src', revision='master')
print("---------------dl_model OK----------------")
def load_vector_database(self) -> ChromaVectorStore:
"""
加载或创建向量数据库
Args:
persist_dir (str): 持久化目录路径
Returns:
ChromaVectorStore: 向量存储对象
"""
# 检查持久化目录是否存在
is_exist = False
if os.path.exists(self.persist_dir):
print(f"正在加载现有的向量数据库: {self.persist_dir}")
chroma_client = chromadb.PersistentClient(path=self.persist_dir)
chroma_collection = chroma_client.get_collection("llama2_paper")
is_exist = True
else:
print(f"创建新的向量数据库: {self.persist_dir}")
chroma_client = chromadb.PersistentClient(path=self.persist_dir)
chroma_collection = chroma_client.create_collection("llama2_paper")
print(f"Vector store loaded with {chroma_collection.count()} documents")
return ChromaVectorStore(chroma_collection=chroma_collection), is_exist
def load_data(self) -> List[TextNode]:
"""
加载并处理PDF数据
Args:
data_path (str): PDF文件路径
Returns:
List[TextNode]: 处理后的文本节点列表
"""
loader = PyMuPDFReader()
documents = loader.load(file_path=self.data_path)
text_parser = SentenceSplitter(chunk_size=384)
text_chunks = []
doc_idxs = []
for doc_idx, doc in enumerate(documents):
cur_text_chunks = text_parser.split_text(doc.text)
text_chunks.extend(cur_text_chunks)
doc_idxs.extend([doc_idx] * len(cur_text_chunks))
nodes = []
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(text=text_chunk)
src_doc = documents[doc_idxs[idx]]
node.metadata = src_doc.metadata
nodes.append(node)
return nodes
def completion_to_prompt(self, completion: str) -> str:
"""
将完成转换为提示格式
Args:
completion (str): 完成的文本
Returns:
str: 格式化后的提示
"""
return f"<|system|>\n</s>\n<|user|>\n{completion}</s>\n<|assistant|>\n"
def messages_to_prompt(self, messages: List[dict]) -> str:
"""
将消息列表转换为提示格式
Args:
messages (List[dict]): 消息列表
Returns:
str: 格式化后的提示
"""
prompt = ""
for message in messages:
if message.role == "system":
prompt += f"<|system|>\n{message.content}</s>\n"
elif message.role == "user":
prompt += f"<|user|>\n{message.content}</s>\n"
elif message.role == "assistant":
prompt += f"<|assistant|>\n{message.content}</s>\n"
if not prompt.startswith("<|system|>\n"):
prompt = "<|system|>\n</s>\n" + prompt
prompt = prompt + "<|assistant|>\n"
return prompt
def setup_llm(self) -> IpexLLM:
"""
设置语言模型
Args:
config (Config): 配置对象
Returns:
IpexLLM: 配置好的语言模型
"""
# config = Config()
return IpexLLM.from_model_id_low_bit(
model_name=self.model_name,
tokenizer_name=self.tokenizer_path,
context_window=384,
max_new_tokens=self.max_new_tokens,
generate_kwargs={"temperature": 0.7, "do_sample": False},
model_kwargs={},
messages_to_prompt=self.messages_to_prompt,
completion_to_prompt=self.completion_to_prompt,
device_map="cpu",
)
def main(self):
"""主函数"""
# 设置嵌入模型
embed_model = HuggingFaceEmbedding(model_name=self.embedding_model_path)
print("---------------OK----------------")
# 加载和处理数据
nodes = self.load_data()
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode="all")
)
node.embedding = node_embedding
# 加载向量数据库
vector_store, is_exist = self.load_vector_database()
# 将 node 添加到向量存储
if not is_exist:
vector_store.add(nodes)
# print("-----OK" * 20)
# 设置查询
# query_str = config.question
query_embedding = embed_model.get_query_embedding(self.question)
# 执行向量存储检索
print("开始执行向量存储检索")
query_mode = "default"
vector_store_query = VectorStoreQuery(
query_embedding=query_embedding, similarity_top_k=2, mode=query_mode
)
query_result = vector_store.query(vector_store_query)
# 处理查询结果
print("开始处理检索结果")
nodes_with_scores = []
for index, node in enumerate(query_result.nodes):
score: Optional[float] = None
if query_result.similarities is not None:
score = query_result.similarities[index]
nodes_with_scores.append(NodeWithScore(node=node, score=score))
# 设置检索器
self.retriever = VectorDBRetriever(
vector_store, embed_model, query_mode="default", similarity_top_k=1
)
def chat(self, question, temperature=0.7, do_sample=False):
# 设置语言模型
llm = IpexLLM.from_model_id_low_bit(
model_name=self.model_name,
tokenizer_name=self.tokenizer_path,
context_window=384,
max_new_tokens=self.max_new_tokens,
generate_kwargs={"temperature": temperature, "do_sample": do_sample},
model_kwargs={},
messages_to_prompt=self.messages_to_prompt,
completion_to_prompt=self.completion_to_prompt,
device_map="cpu",
)
print("准备与llm对话")
query_engine = RetrieverQueryEngine.from_args(self.retriever, llm=llm)
# 执行查询
print("开始RAG最后生成")
start_time = time.time()
response = query_engine.query(question)
# 打印结果
print("------------RESPONSE GENERATION---------------------")
print(str(response))
print(f"inference time: {time.time()-start_time}")
return str(response)
# 设置Gradio界面
def gradio_chat_interface(self,question, temperature=0.7, do_sample=False):
question = question + "\n请用中文回答。"
return self.chat(question, temperature, do_sample)
if __name__ == "__main__":
r = RuanKao()
r.dl_model()
r.main()
# 获取脚本所在目录的绝对路径
script_dir = os.path.dirname(os.path.abspath(__file__))
# 图片的绝对路径
bg_image_path = "https://img.it-worker.club/bg.jpg"
print(bg_image_path)
# CSS样式,设置背景图片和透明度
css = f"""
body {{
background: url('{bg_image_path}') no-repeat center center fixed;
background-size: cover;
background-color: rgba(0, 0, 0, 0.5);
}}
.gradio-container {{
background-color: rgba(255, 255, 255, 0.8);
border-radius: 10px;
padding: 20px;
}}
"""
with gr.Blocks(css=css) as demo:
gr.Markdown("# IT知识智能问答系统")
with gr.Row():
question = gr.Textbox(lines=2, placeholder="请输入你的问题...")
temperature = gr.Slider(minimum=0.0, maximum=1.0, label="Temperature")
do_sample = gr.Checkbox(label="Do Sample")
output = gr.Textbox()
btn = gr.Button("Submit")
btn.click(r.gradio_chat_interface, inputs=[question, temperature, do_sample], outputs=output)
demo.launch(share=True)
data目录下的PDF的下载地址:https://github.com/openvinotoolkit/openvino_notebooks/files/15039713/Platform.Brief_Intel.vPro.with.Intel.Core.Ultra_Final_CH.pdf
代码运行效果如下
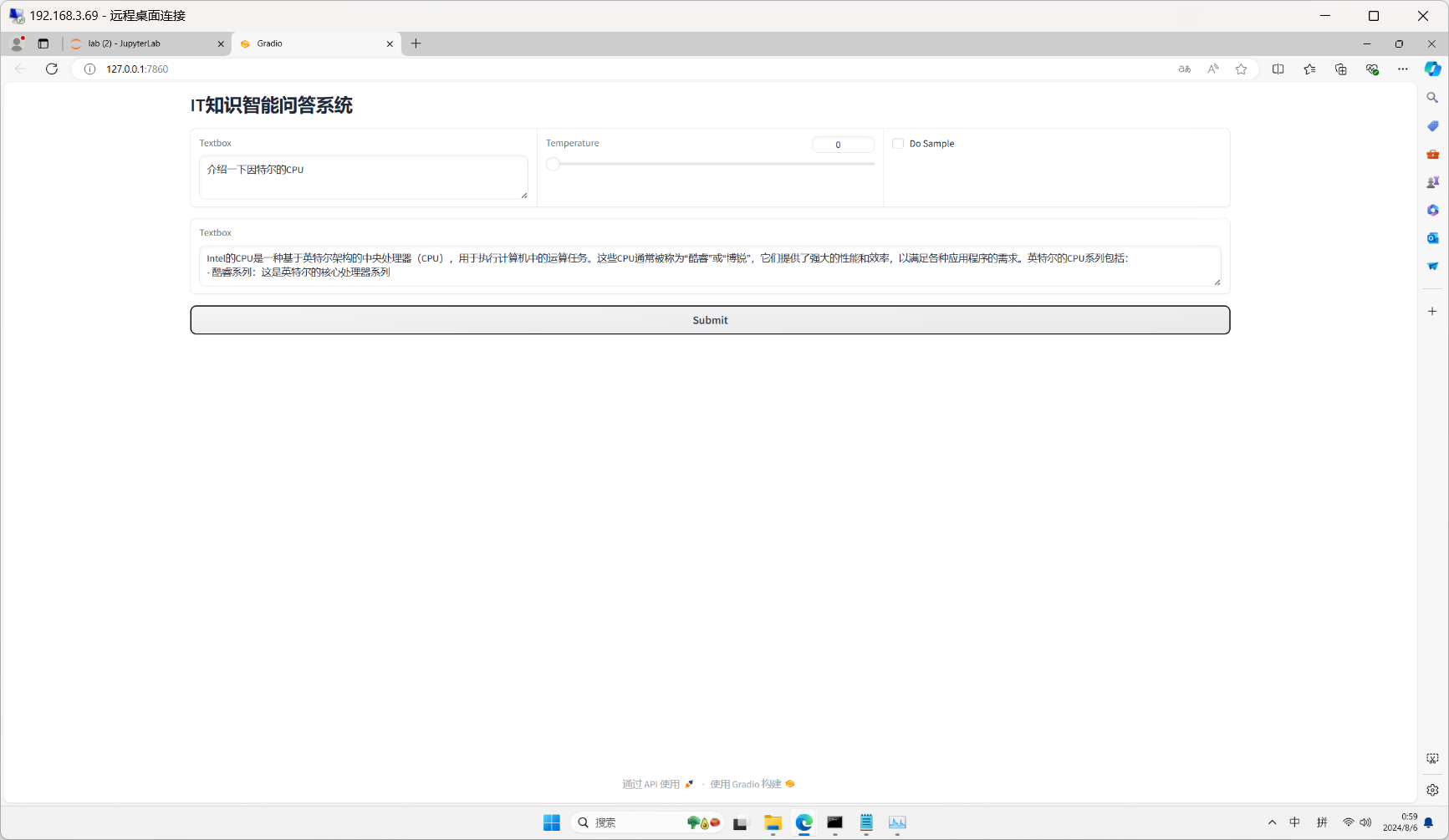
总结
我们可以看到,基于IPEX这个框架,可以很好的将LLM + RAG部署在本地。总统体验还是很流畅,希望能给各位开发者提供一些帮助。我是Tango,一个热爱分享技术的程序猿我们下期见。
视频演示大家可以到我的B站首页查看相关内容:视频演示

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)