【哪吒开发板试用】基于FunASR架构的离线音频转文字
一、项目简介 本项目基于哪吒开发板,利用 FunASR 框架,实现了离线音频转文字的功能。该项目还使用了Docker进行部署,简化了配置流程。 二、开发板简介 哪吒(Nezha)开发套件以信用卡大小(85 x 56mm)的开发板-哪吒(Nezha)为核心,采用
一、项目简介
本项目基于哪吒开发板,利用 FunASR 框架,实现了离线音频转文字的功能。该项目还使用了Docker进行部署,简化了配置流程。
二、开发板简介
哪吒(Nezha)开发套件以信用卡大小(85 x 56mm)的开发板-哪吒(Nezha)为核心,采用英特尔®处理器 N97(Alder Lake-N),结合了高性能和低功耗的特性。它支持四核 SoC,时钟频率高达 3.60GHz,TDP 仅为 12W。 其内置 GPU 用于 高分辨率显示。哪吒保持了 85mm x 56mm 信用卡大小的外形尺寸,与树莓派相同,包括高达 8GB 的 LPDDR5 系统内存、高达 64GB 的 eMMC 存储、板载 TPM 2.0、40 针 GPIO 连接器,并支持 Windows 和 Linux 操作系统。这些功能与无风扇冷却器相结合,为各种应用构建了高效的解决方案,适用于教育、物联网网关、数字标牌和机器人等应用。

三、技术路线
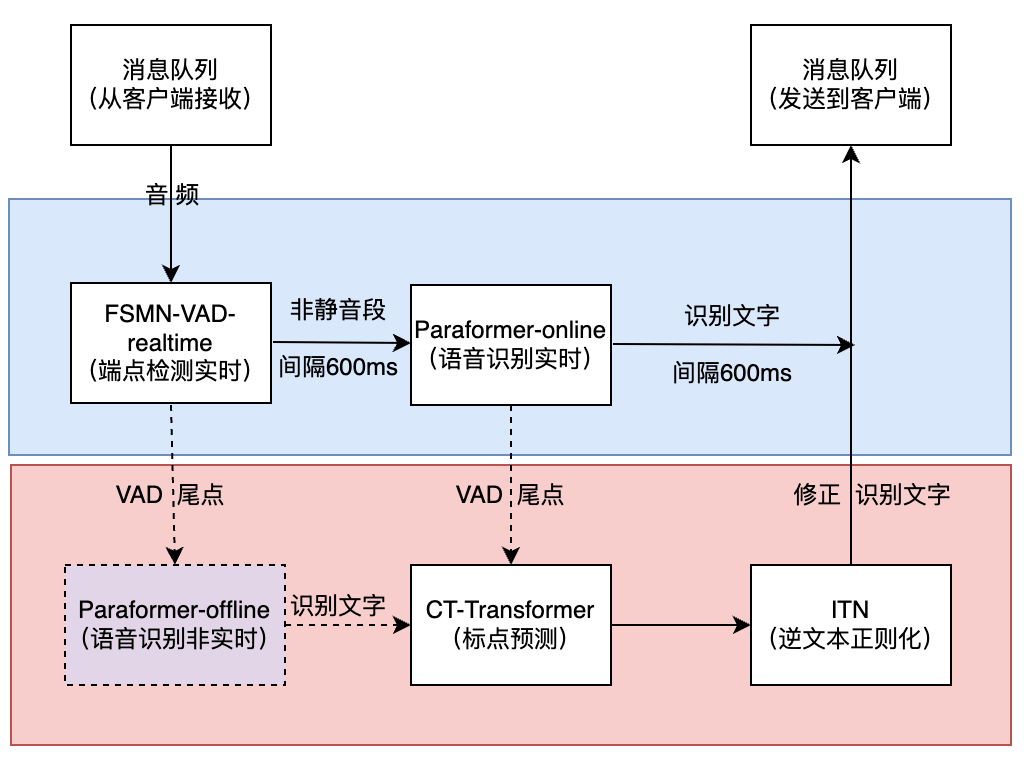
3.1FunASR框架
3.2 环境搭建
- 由于开发板储存有限,项目使用的Docker镜像和模型总占用约10G,因此第一步就是安装Ubuntu操作系统。本项目使用Ubuntu版本为20.04,安装步骤可参考 哪吒开发板Linux系统安装教程。
- 安装Docker,python。下载Docker 镜像:
python依赖如下:docker pull registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.5
# requirements.txt
aiofiles==24.1.0
aliyun-python-sdk-core==2.16.0
aliyun-python-sdk-kms==2.16.5
annotated-types==0.7.0
antlr4-python3-runtime==4.9.3
anyio==4.6.2
asyncio==3.4.3
audioread==3.0.1
certifi==2024.8.30
cffi==1.17.1
charset-normalizer==3.4.0
click==8.1.7
crcmod==1.7
cryptography==43.0.1
decorator==5.1.1
editdistance==0.8.1
fastapi==0.115.2
ffmpeg-python==0.2.0
funasr==1.1.12
future==1.0.0
h11==0.14.0
hydra-core==1.3.2
idna==3.10
jaconv==0.4.0
jamo==0.4.1
jieba==0.42.1
jmespath==0.10.0
joblib==1.4.2
kaldiio==2.18.0
lazy_loader==0.4
librosa==0.10.2.post1
llvmlite==0.43.0
modelscope==1.18.1
msgpack==1.1.0
numba==0.60.0
numpy==2.0.2
omegaconf==2.3.0
oss2==2.19.0
packaging==24.1
platformdirs==4.3.6
pooch==1.8.2
protobuf==5.28.2
pycparser==2.22
pycryptodome==3.21.0
pydantic==2.9.2
pydantic_core==2.23.4
pynndescent==0.5.13
python-multipart==0.0.12
pytorch-wpe==0.0.1
PyYAML==6.0.2
requests==2.32.3
scikit-learn==1.5.2
scipy==1.14.1
sentencepiece==0.2.0
six==1.16.0
sniffio==1.3.1
soundfile==0.12.1
soxr==0.5.0.post13.3模型搭建
由于funASR社区提供的http服务部署起来困难,且社区没有相应的解决方案,且官方对websocket版本维护更好,因此我们采用自研http服务转发官方的websocket服务的形式实现,当前服务在cpu上实现很快的识别速度,对于短音频相比python gpu版本速度提升45%,并且服务支持多路并发,同时支持热词定制。
目前采用的模型列表如下(建议从modelscope下载模型):
-
ASR 语音识别:speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
-
VAD 语音端点检测,可支持长音频: speech_fsmn_vad_zh-cn-16k-common-pytorch
-
PUNC 标点符号生成:punc_ct-transformer_zh-cn-common-vocab272727-pytorch
-
ITN 文本规整:fst_itn_zh
本项目使用C++服务,使用前需要将以上pt模型转换成onnx量化模型,转换方式如下所示:
from funasr import AutoModel
model = AutoModel(
model=("/path/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch")
)
res = model.export(type="onnx", quantize=True)
print(res)
3.4 离线转写部署流程
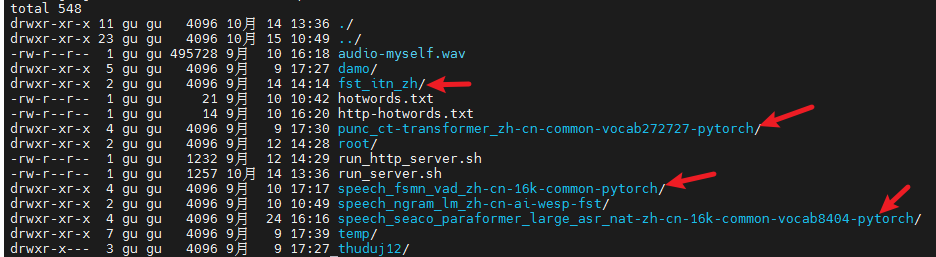
- 进入根目录, cd ~。在根目录新建 model-onnx-cpu目录,将模型文件拷进去(记得先转换onnx,最好在funasr-cpu镜像中挂载转换,防止版本冲突),如下图所示,红色箭头指向的就是模型目录:
-
添加model-onnx-cpu/hotwords.txt,里面加入所需要的热词,示例如下(<文本 权重>格式):
用例 20
浦沿 20
-
添加model-onnx-cpu/run_server.sh,如下:
download_model_dir="/workspace/models"
model_dir="/workspace/models/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
vad_dir="/workspace/models/speech_fsmn_vad_zh-cn-16k-common-pytorch"
punc_dir="/workspace/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
itn_dir="/workspace/models/fst_itn_zh"
lm_dir=""
port=10095
certfile=""
keyfile=""
hotword="/workspace/models/hotwords.txt"
# set decoder_thread_num
decoder_thread_num=$(cat /proc/cpuinfo | grep "processor"|wc -l) || { echo "Get cpuinfo failed. Set decoder_thread_num = 32"; decoder_thread_num=32; }
multiple_io=16
io_thread_num=$(( (decoder_thread_num + multiple_io - 1) / multiple_io ))
model_thread_num=1
cmd_path=/workspace/FunASR/runtime/websocket/build/bin
cmd=funasr-wss-server
cd $cmd_path
$cmd_path/${cmd} \
--download-model-dir "${download_model_dir}" \
--model-dir "${model_dir}" \
--vad-dir "${vad_dir}" \
--punc-dir "${punc_dir}" \
--itn-dir "${itn_dir}" \
--lm-dir "${lm_dir}" \
--decoder-thread-num ${decoder_thread_num} \
--model-thread-num ${model_thread_num} \
--io-thread-num ${io_thread_num} \
--port ${port} \
--certfile "${certfile}" \
--keyfile "${keyfile}" \
--hotword "${hotword}"
-
根目录下添加cppserver.py,--temp_dir变量的默认值需要改成能访问的地址。如下:
import argparse
import asyncio
import logging
import os
import uuid
import aiofiles
import ffmpeg
import uvicorn
from fastapi import FastAPI, File, UploadFile
from modelscope.utils.logger import get_logger
import time
import json
import websockets
logger = get_logger(log_level=logging.INFO)
logger.setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--host", type=str, default="0.0.0.0", required=False, help="host ip, localhost, 0.0.0.0"
)
parser.add_argument("--port", type=int, default=8020, required=False, help="server port")
parser.add_argument("--temp_dir", type=str, default="temp_dir_cpp/", required=False, help="temp dir")
#[5, 10, 5] 600ms, [8, 8, 4] 480ms
parser.add_argument("--chunk_size", type=str, default="5, 10, 5", help="chunk")
#number of chunks to lookback for encoder self-attention
parser.add_argument("--encoder_chunk_look_back", type=int, default=4, help="chunk")
#number of encoder chunks to lookback for decoder cross-attention
parser.add_argument("--decoder_chunk_look_back", type=int, default=0, help="chunk")
parser.add_argument("--chunk_interval", type=int, default=10, help="chunk")
args = parser.parse_args()
args.chunk_size = [int(x) for x in args.chunk_size.split(",")]
logger.info("----------- Configuration Arguments -----------")
for arg, value in vars(args).items():
logger.info("%s: %s" % (arg, value))
logger.info("------------------------------------------------")
os.makedirs(args.temp_dir, exist_ok=True)
app = FastAPI(title="FunASRCpp")
async def record_from_scp(audio_path):
hotword_msg = ""
use_itn = True
audio_name = "demo"
sample_rate = 16000
audio_bytes, _ = (
ffmpeg.input(audio_path, threads=0)
.output("-", format="s16le", acodec="pcm_s16le", ac=1, ar=16000)
.run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True)
)
stride = int(60 * args.chunk_size[1] / args.chunk_interval / 1000 * sample_rate * 2)
chunk_num = (len(audio_bytes) - 1) // stride + 1
# send first time
message = json.dumps(
{
"mode": "offine",
"chunk_size": args.chunk_size,
"chunk_interval": args.chunk_interval,
"encoder_chunk_look_back": args.encoder_chunk_look_back,
"decoder_chunk_look_back": args.decoder_chunk_look_back,
"audio_fs": sample_rate,
"wav_name": audio_name,
"wav_format": "pcm",
"is_speaking": True,
"hotwords": hotword_msg,
"itn": use_itn,
}
)
uri = "ws://{}:{}".format("127.0.0.1", "10097")
ssl_context = None
async with websockets.connect(
uri, subprotocols=["binary"], ping_interval=None, ssl=ssl_context
) as websocket:
await websocket.send(message)
await websocket.send(audio_bytes)
message = json.dumps({"is_speaking": False})
await websocket.send(message)
# for i in range(chunk_num):
# beg = i * stride
# data = audio_bytes[beg : beg + stride]
# message = data
# await websocket.send(message)
# if i == chunk_num - 1:
# is_speaking = False
# message = json.dumps({"is_speaking": is_speaking})
# await websocket.send(message)
# sleep_duration = 0.001
# await asyncio.sleep(sleep_duration)
start_time = time.time()
print(start_time)
msg = await websocket.recv()
start_time = time.time()
print(start_time)
msg = json.loads(msg)
text = msg["text"]
return text
@app.post("/recognition")
async def api_recognition(audio: UploadFile = File(..., description="audio file")):
suffix = audio.filename.split(".")[-1]
audio_path = f"{args.temp_dir}/{str(uuid.uuid1())}.{suffix}"
async with aiofiles.open(audio_path, "wb") as out_file:
content = await audio.read()
await out_file.write(content)
try:
start_time = time.time()
print(start_time)
text = await record_from_scp(audio_path)
end_time = time.time()
distance_time = end_time - start_time
return {"text": text, "sentences": [], "code": 0, "time": str(distance_time) + "s"}
except Exception as e:
logger.error(f"调用asr服务发生错误:{e}")
return {"msg": "调用asr服务发生错误", "code": -1}
if __name__ == "__main__":
uvicorn.run(
app, host=args.host, port=args.port, ssl_keyfile=None, ssl_certfile=None
)
- 根目录下添加添加start_asr.sh,需要把python环境地址,cppserver.py所在地址进行修改。如下:
#!/bin/bash
source /PATH/TO/anaconda3/bin/activate asr # 改成你自己的环境地址
# 停止docker
service_name="http-asr"
docker_ps_output=$(docker ps -a --format "{{.Names}}" | grep $service_name)
if [ -z "$docker_ps_output" ]; then
echo "未找到Docker服务:$service_name"
else
echo "找到Docker服务:$service_name"
echo "停止Docker服务:$service_name"
docker stop $docker_ps_output
docker rm $docker_ps_output
fi
# 停止进程
ps -ef | grep "cppserver.py" | grep -v grep | awk '{print $2}' | xargs kill -9
lsof -i:10097 | tail -n +2 | awk '{print $2}' | xargs kill -9
lsof -i:8020 | tail -n +2 | awk '{print $2}' | xargs kill -9
# 启动docker
docker run --detach -p 10097:10095 --name=http-asr --privileged=true -v /root/model-onnx-cpu:/workspace/models registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.5 /bin/bash /workspace/models/run_server.sh
# 启动python服务
nohup python /PATH/TO/cppserver.py > pylog.out &-
执行start_asr.sh脚本,更改ip地址,启动后进行测试(替换成自己本地音频路径,Linux可以直接执行以下命令验证,Windows可以通过postman验证):
curl --location 'http://xxx.xxx.xxx.xxx:8020/recognition' --form 'audio=@"/PATH/TO/audio-file"'- 执行结果如下图所示:
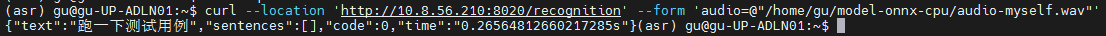

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)