从0到1构建 OpenVINO™ 智能体流水线
作者:杨亦诚 英特尔 AI 软件工程师 智能体 AI Agent 作为大模型的衍生应用,具有对任务的理解、规划与行动能力。它可以通过将一个复杂的用户请求拆分成不同的子任务,并依次调用外部工具来解决这些任务,并将其中每个任务步骤的执行结果,按预先规划的逻辑串联起来,从而达成最终的目的。 接下来我们就通过一个例子&#x
作者:杨亦诚 英特尔 AI 软件工程师
智能体 AI Agent 作为大模型的衍生应用,具有对任务的理解、规划与行动能力。它可以通过将一个复杂的用户请求拆分成不同的子任务,并依次调用外部工具来解决这些任务,并将其中每个任务步骤的执行结果,按预先规划的逻辑串联起来,从而达成最终的目的。
接下来我们就通过一个例子,演示如何利用 OpenVINO™ 工具套件在你的电脑上的一步步搭建本地智能体流水线。
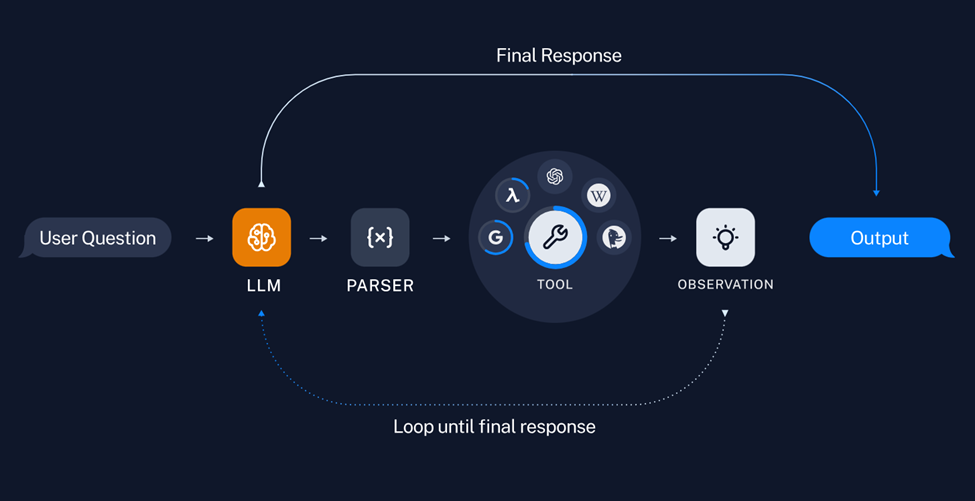
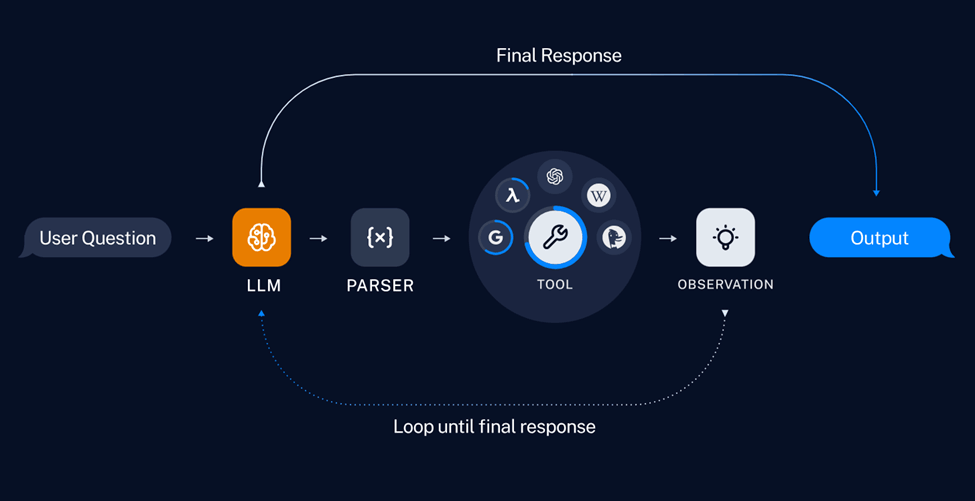
图:智能体流水线
示例地址:
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/llm-agent-react/llm-agent-react.ipynb
1. 转换压缩LLM
首先要需要利用 Hugging Face 的 Optimum-intel 命令行工具将原始模型转化为 OpenVINO™ 的 IR 格式,并对其进行 int4 量化压缩,以实现本地部署的目的。这里我们选择通义千问团队近期发布的 Qwen2.5 大语言模型为例,它可以支持多种不同语言。其中最小3B参数版本的模型便可以对本示例进行复现。
!optimum-cli export openvino --model "Qwen/Qwen2.5-3B-Instruct"--task text-generation-with-past --trust-remote-code --weight-format int4 --group-size 128 --ratio 1.0 --sym “Qwen2.5-3B-Instruct-int4-ov”
其中"Qwen/Qwen2.5-3B-Instruct"为模型的 HuggingFace 的模型 ID,如果在访问 Hugging Face 模型仓库时,发现网络限制,也可以通过 ModelScope 将原始模型下载到本地,并将该模型 ID 替换为模型的本地路径,例如:"./model/Qwen2.5-3B-Instruct"。
ModelScope下载模型的方法参考:
https://www.modelscope.cn/docs/%E6%A8%A1%E5%9E%8B%E7%9A%84%E4%B8%8B%E8%BD%BD
2. 创建LLM任务
第二步同样可以利用 Optimum-intel 提供的 OpenVINO™ API 接口将模型部署在指定的硬件平台,这里可以通过指定 device=”gpu” 将模型加载到任意一个 Intel 的独显或是集显上,以最大化模型推理性能。
tokenizer = AutoTokenizer.from_pretrained(llm_model_path, trust_remote_code=True)
ov_config = {hints.performance_mode(): hints.PerformanceMode.LATENCY, streams.num(): "1", props.cache_dir(): ""}
llm = OVModelForCausalLM.from_pretrained(
llm_model_path,
device=llm_device.value,
ov_config=ov_config,
config=AutoConfig.from_pretrained(llm_model_path, trust_remote_code=True),
trust_remote_code=True,
)除了对模型对象进行初始化以外,还需要创建针对模型推理输出的后处理函数,主要目的是为了实现流式输出,以及设置停止字符,让 LLM 在调用工具前停止推理任务。
def text_completion(prompt: str, stop_words) -> str:
im_end = "<|im_end|>"
if im_end not in stop_words:
stop_words = stop_words + [im_end]
streamer = TextStreamer(tokenizer, timeout=60.0, skip_prompt=True, skip_special_tokens=True)
stopping_criteria = StoppingCriteriaList([StopSequenceCriteria(stop_words, tokenizer)])
input_ids = torch.tensor([tokenizer.encode(prompt)])
generate_kwargs = dict(
input_ids=input_ids,
streamer=streamer,
stopping_criteria=stopping_criteria,
)
output = llm.generate(**generate_kwargs)
output = output.tolist()[0]
output = tokenizer.decode(output, errors="ignore")
assert output.startswith(prompt)
output = output[len(prompt) :].replace("<|endoftext|>", "").replace(im_end, "")
for stop_str in stop_words:
idx = output.find(stop_str)
if idx != -1:
output = output[: idx + len(stop_str)]
return output
3. 定义智能体Prompt模板
这一步也是决定智能体工作模式的关键,通过 Prompt 模板,我们将教会 LLM 一个常规任务的解决路径,以及有哪些类别的外部工具可能帮助它解决特定问题。可以看到在下面这个典型 ReAct 类 Prompt 模板中,我们定义外部工具的具体信息模板,以及 LLM 在执行任务过程中的输出模板,其中 “Observation” 后内容为外部工具调用后返回的结果,并非由 LLM 直接生成。可以看到在该模板中, LLM 可能会被执行多次,直到上下文中的信息足够回答用户请求。
TOOL_DESC = """{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters}"""
PROMPT_REACT = """Answer the following questions as best you can. You have access to the following APIs:
{tools_text}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tools_name_text}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {query}"""
4. 输出过滤与工具定义
由于智能体需要和外部工具频繁交互,发出指令并获取工具反馈结果,因此我们需要在 LLM 输出时,判断哪些关键词代表模型需要调用工具,哪些关键词代表收集工具反馈结果。在这里例子中,当 LLM 输出 “Action:" 后的字符,代表接下来需要调用的工具函数名称,输出 “Action Input” 后的字符,代表输入给该工具的输入参数,以及 “Observation” 代表接下来需要直接输出工具的执行结果,因此它也是终止当前 LLM 推理任务的特殊字符。
def parse_latest_tool_call(text):
tool_name, tool_args = "", ""
i = text.rfind("\nAction:")
j = text.rfind("\nAction Input:")
k = text.rfind("\nObservation:")
if 0 <= i < j: # If the text has `Action` and `Action input`,
if k < j: # but does not contain `Observation`,
# then it is likely that `Observation` is ommited by the LLM,
# because the output text may have discarded the stop word.
text = text.rstrip() + "\nObservation:" # Add it back.
k = text.rfind("\nObservation:")
tool_name = text[i + len("\nAction:") : j].strip()
tool_args = text[j + len("\nAction Input:") : k].strip()
text = text[:k]
return tool_name, tool_args, text
为了告诉 LLM 什么时候该调用什么工具,以及这些工具的基本输入和输入参数格式,我们在完成工具函数的编写后,还需要以字典的形式,将这些信息送入先前定义的 Prompt 模板中,参考示例如下:
tools = [
{
"name_for_human": "get weather",
"name_for_model": "get_weather",
"description_for_model": 'Get the current weather in a given city name."',
"parameters": [
{
"name": "city_name",
"description": "City name",
"required": True,
"schema": {"type": "string"},
}
],
},
{
"name_for_human": "image generation",
"name_for_model": "image_gen",
"description_for_model": "AI painting (image generation) service, input text description, and return the image URL drawn based on text information.",
"parameters": [
{
"name": "prompt",
"description": "describe the image",
"required": True,
"schema": {"type": "string"},
}
],
},
]
在这个例子中,我们定义一个天气查询工具以及一个文生图工具,他们分别会调用响应的 API 服务完成响应任务。
5. 构建智能体
接下来我们需要将以上定义的函数串联起来,构建一个简单的智能体流水线。第一步会将用户请求经 Prompt 模板格式化后送入 LLM,接下来解析 LLM 输出,并判断是否需要调用外部工具 “Action” 。如果需要调用外部工具,则智能体会运行该工具函数,获得运行结果,最后将结果数据合并到下一轮的输入 Prompt 中,由 LLM 判断是否还需要再次调用其他工具,再进行一次循环,如果不需要调用工具,并且当前得到的信息已经可以满足用户请求,那 LLM 将整合并基于这个过程中所有的 “Observation” 信息,输出最终答案 “Final Answer”。
while True:
output = text_completion(planning_prompt + text, stop_words=["Observation:", "Observation:\n"])
action, action_input, output = parse_latest_tool_call(output)
if action:
observation = call_tool(action, action_input)
output += f"\nObservation: = {observation}\nThought:"
observation = f"{observation}\nThought:"
print(observation)
text += output
else:
text += output
break
该示例的运行效果如下,这里我们让智能体“根据当前伦敦的天气,生成一张大本钟的照片”。可以看到智能体按照我们既定的 Prompt 策略,将用户问题拆分后,分别调用预先定义的不同工具,根据用户要求得到最终结果。当然你也可以用中文向它发出请求。
query = "get the weather in London, and create a picture of Big Ben based on the weather information"
response, history = llm_with_tool(prompt=query, history=history, list_of_tool_info=tools)
“Thought: First, I need to use the get_weather API to get the current weather in London.Action: get_weather
Action Input: {"city_name": "London"}
Observation:
{'current_condition': {'temp_C': '11', 'FeelsLikeC': '10', 'humidity': '94', 'weatherDesc': [{'value': 'Overcast'}], 'observation_time': '12:23 AM'}}
Thought:
Now that I have the weather information, I will use the image_gen API to generate an image of Big Ben based on the weather conditions.
Action: image_gen
Action Input: {"prompt": "Big Ben under overcast sky with temperature 11°C and humidity 94%"}
Observation:
{"image_url": "https://image.pollinations.ai/prompt/Big%20Ben%20under%20overcast%20sky%20with%20temperature%2011%C2%B0C%20and%20humidity%2094%25"}
Thought:
The image has been generated successfully.
Final Answer: The current weather in London is overcast with a temperature of 11°C and humidity of 94%. Based on this information, here is the image of Big Ben under an overcast sky: “
6. 总结
该示例以 OpenVINO™ 作为 LLM 的推理后端,一步步构建起了一个简单的智能体流水线,可以看到这个示例中除了 Optimum-intel,没有其他外部依赖需要安装,因此它也是一个非常基础的的智能体构建过程。除此以外,该示例使用 3B 大小 SLM 便可以实现该智能体的构建,同时带来不错的性能表现,是非常适合在本地构建的智能体示例。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 0
0 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)