Qwen3 Day0 deployment on Intel OpenVINO™
Ethan Yang
Qwen3, the latest text generation model series released by Alibaba’s Tongyi team, offers a comprehensive suite of dense and mixture-of-experts (MoE) models.Trained on vast datasets, Qwen3 advances reasoning, instruction-following, agent capabilities, and multilingual performance.
This blog shows how to deploy the Qwen3 series, using Qwen3-8B as an example, on Intel® platforms (GPU, NPU) using the OpenVINO™ toolkit and Python API.
The OpenVINO™ toolkit empowers developers to rapidly build LLM-based applications, leveraging Intel AIPC heterogeneous computing power for efficient inference.
Table of Contents
- Environment Preparation
- Model Download and Conversion
- Model Deployment
Step1. Environment Preparation
Use the following commands to set up the Python environment for model deployment:
python -m venv py_venv
./py_venv/Scripts/activate.bat
pip install --pre -U openvino-genai openvino openvino-tokenizers --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
pip install nncf
pip install git+https://github.com/huggingface/optimum-intel.git
pip install transformers >=4.51.3
Step2. Model Download and Conversion
Before deployment,convert the original PyTorch model to OpenVINO™'s Intermediate Representation (IR) format and optionally compress it for lightweight, high-performance inference. Use the optimum-cli tool for conversion and quantization:
optimum-cli export openvino --model Qwen/Qwen3-8B --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 Qwen3-8B-int4-ov Developers can adjust quantization parameters based on model output results, including:
- --model: The model ID on HuggingFace. For local models, replace it with the local path. For PRC developers, ModelScope is recommended for model downloads.
- --weight-format: Quantization precision (options: fp32, fp16, int8, int4, etc.).
- --group-size: Number of channels sharing quantization parameters.
- --ratio: int4/int8 weight ratio (default: 1.0).
- --sym: Enable symmetric quantization.
For quantization optimized for Intel® NPU:
optimum-cli export openvino --model Qwen/Qwen3-8B --task text-generation-with-past --weight-format nf4 --sym --group-size -1 Qwen3-8B-nf4-ov --backup-precision int8_symStep3. Model Deployment
OpenVINO™ currently offers two deployment methods for large language models (LLMs). If you are accustomed to deploying models via the Transformers library interface and seek functionality, it is recommended to use the Python-based Optimum-intel tool for task implementation. For those aiming for peak performance or lightweight deployment, OpenVINO™ GenAI is the optimal choice. It supports both Python and C++ programming languages, with an installation footprint of less than 200MB.
OpenVINO™ offers two deployment approaches for large language models:
- Optimum-intel Deployment Example
from optimum.intel.openvino import OVModelForCausalLM
from transformers import AutoConfig, AutoTokenizer
ov_model = OVModelForCausalLM.from_pretrained(
llm_model_path,
device='GPU',
)
tokenizer = AutoTokenizer.from_pretrained(llm_model_path)
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([text], return_tensors="pt")
generated_ids = ov_model.generate(**model_inputs, max_new_tokens=1024)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)- OpenVINO GenAI Deployment Example
import openvino_genai as ov_genai
generation_config = ov_genai.GenerationConfig()
generation_config.max_new_tokens = 128
generation_config.apply_chat_template = False
pipe = ov_genai.LLMPipeline(llm_model_path, "GPU")
result = pipe.generate(prompt, generation_config)To deploy the model on NPU, you can switch the device name from “GPU” to “NPU”.
pipe = ov_genai.LLMPipeline(llm_model_path, "NPU")To enable streaming mode, you can customize a streamer for OpenVINO™ GenAI pipeline.
def streamer(subword):
print(subword, end='', flush=True)
sys.stdout.flush()
return False
pipe.generate(prompt, generation_config, streamer=streamer)
Additionally, the GenAI API provides a chat mode implementation. By invoking pipe.start_chat() and pipe.finish_chat(), history data from multi-turn conversations is managed in memory as Caches are a crucial optimization technique in the generation phase of auto-regressive models. They store pre-computed key (K) and value (V) elements, which help speed up the generation process by allowing the model to retrieve previously computed data.
pipe.start_chat()
while True:
try:
prompt = input('question:\n')
except EOFError:
break
pipe.generate(prompt, generation, streamer)
print('\n----------')
pipe.finish_chat()
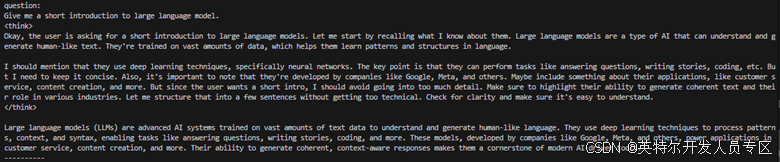
pipe.start_chat()
while True:
try:
prompt = input('question:\n')
except EOFError:
break
pipe.generate(prompt, generation, streamer)
print('\n----------')
pipe.finish_chat()Conclusion
Whether using Optimum-intel or OpenVINO™ GenAI , developers can easily deploy Qwen3 models on Intel hardware platform. OpenVINO GenAI is the preferred path for efficient, lightweight, and production-ready LLM deployments across client and edge environments.
Reference:
- llm-chatbot notebook: https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot
- OpenVINO™ GenAI: https://github.com/openvinotoolkit/openvino.genai

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 19
19 0
0- 0



 已为社区贡献328条内容
已为社区贡献328条内容

所有评论(0)