OpenVINO™2025与QWen-VL多模态视觉模型实现零样本对象检测
QWen2.5-VL视觉多模态大模型支持通过生成边框或点来精确定位图像中的对象,并能为坐标和属性提供稳定的 JSON 输出,不仅能熟练识别花、鸟、鱼和昆虫等常见物体、还可以精准检测多种水果、交通工具、动物与人类,可以零代码实现超过300种以上的对象检测并输出它们的JSON格式坐标位置信息与标签信息。
·
对象检测支持
QWen2.5-VL视觉多模态大模型支持通过生成边框或点来精确定位图像中的对象,并能为坐标和属性提供稳定的 JSON 输出,不仅能熟练识别花、鸟、鱼和昆虫等常见物体、还可以精准检测多种水果、交通工具、动物与人类,可以零代码实现超过300种以上的对象检测并输出它们的JSON格式坐标位置信息与标签信息。
模板与提示词
QWen2.5-VL对象检测依赖于正确的提示词与输入格式,qwen2.5_3b当前支持的图像分辨率从256~1280之间,根据提示词实现目标检测位置定位输出标准化的 JSON 格式文档。当需要使用QWen2.5-VL实现对象检测适合,输入输入需要:
图像:一张需要目标识别的图像提示词:给出QWen2.5-VL能听懂的并输出JSON格式目标位置与标签的咒语。
格式如下:
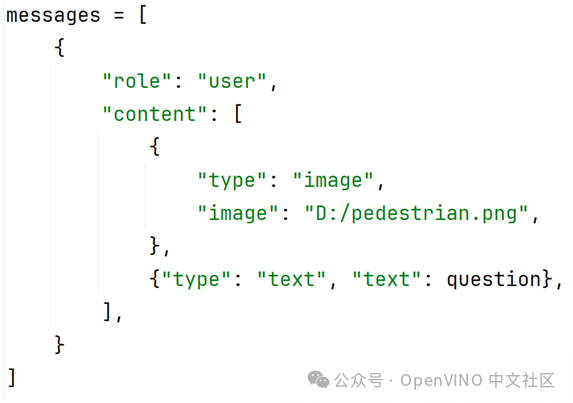
其中prompt就是question的内容,推荐用以下两个提示词之一:
prompt1 = "Outline the position of each person and output all the coordinates in JSON format"prompt2 = 'Detect all objects in the image and give the coordinates. The format of output should be like {"bbox_2d": [x1, y1, x2, y2], "label": label'
代码演示
当前加载Qwen-VL模型OpenVINO™支持的是通过optimum插件方式完成,支持代码如下:
from optimum.intel.openvino import OVModelForVisualCausalLMmin_pixels = 256 * 28 * 28max_pixels = 1280 * 28 * 28model_dir = "D:/LLMs/qwen2.5_3b/INT4"processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)model = OVModelForVisualCausalLM.from_pretrained(model_dir, device="CPU")if processor.chat_template is None:tok = AutoTokenizer.from_pretrained("D:/LLMs/qwen2.5_3b")processor.chat_template = tok.chat_template
加载以后构建包含输入图像与特定提示词会话模板,然后把模板输入到模型,对获取的输出部分JSON数据进行文本解析,文本解析部分的代码如下:
output_text = processor.batch_decode(generated_ids,skip_special_tokens=True,clean_up_tokenization_spaces=True)boxes = []lines = output_text[0].splitlines()for i, line in enumerate(lines):print("number of line: ", i , line)if line.strip().startswith("{\"bbox_2d\": ["):temp = line.strip().replace("us", "[")res = temp.split(", ")x1 = res[0].split(" ")[-1]y1 = res[1]x2 = res[2]y2 = res[3][:len(res[3])-1]print("box: ", x1, y1, x2, y2)boxes.append([x1, y1, x2, y2])for i, box in enumerate(boxes):abs_x1 = int(box[0])abs_y1 = int(box[1])abs_x2 = int(box[2])abs_y2 = int(box[3])if abs_x1 > abs_x2:abs_x1, abs_x2 = abs_x2, abs_x1if abs_y1 > abs_y2:abs_y1, abs_y2 = abs_y2, abs_y1cv.rectangle(image, (abs_x1, abs_y1), (abs_x2, abs_y2), (0, 0, 255), 2)cv.imshow("OpenVINO2025+QWen2.5 Multi-Models", image)cv.waitKey(0)cv.destroyAllWindows()
运行结果,预测输出的JSON格式文档如下:
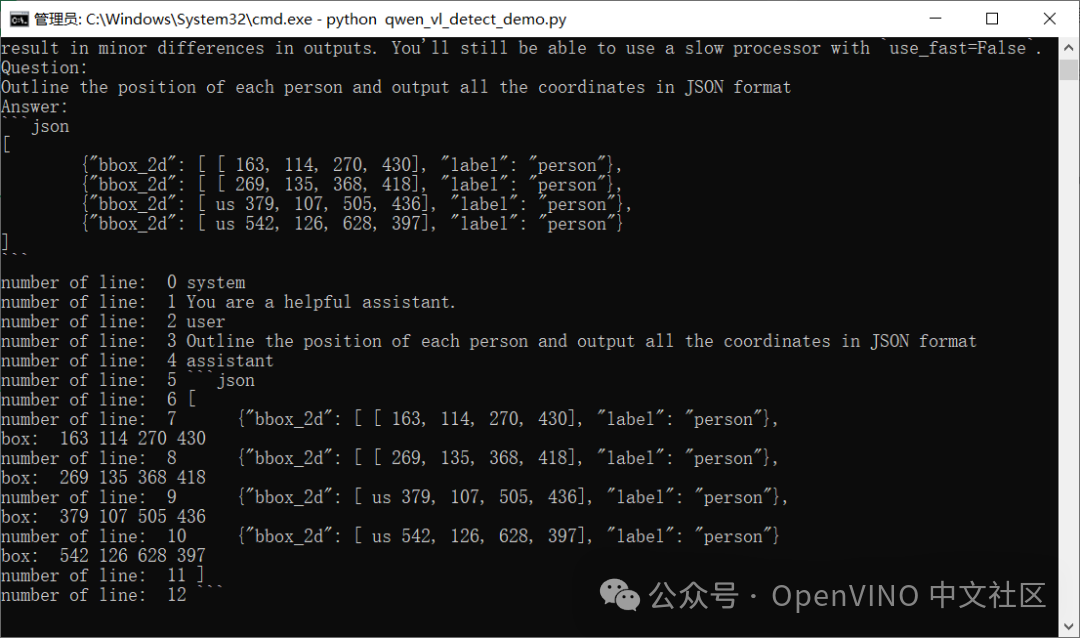
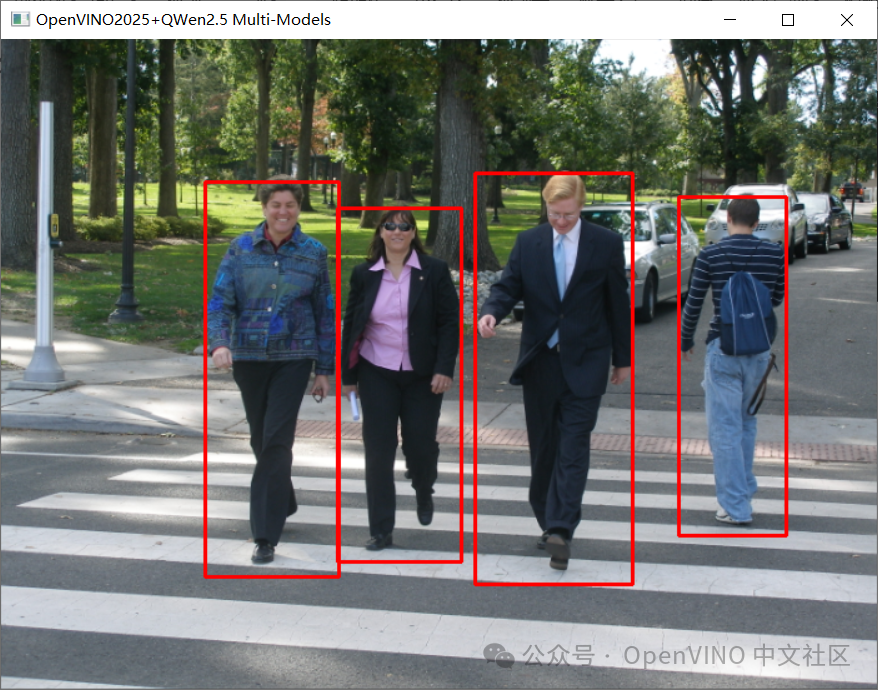
解析JSON格式,绘制BOX位置信息到图像上,显示如下:
用OpenVINO™2025本地部署大模型多块好省,CPU就可以实现大模型部署自由,真的不是梦。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐


 5
5 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)