加速英特尔® GPU上的大语言模型(LLM):动态量化实用指南
作者:Mingyu Kim,高级资深工程师;武卓,AI 软件布道师
动态量化是一种强大的优化技术,能显著提升 Transformer 模型在英特尔® GPU(具备 XMX 硬件,如 Lunar Lake、Arrow Lake 以及 Alchemist、Battlemage 等系列的集成及独立显卡)上的性能。
本文将探讨:
-
什么是动态量化以及它在 OpenVINO™ 2025.2 中如何在 GPU 上工作
-
默认行为和配置选项
-
性能与精度的权衡
-
启用或禁用它的代码示例
-
如何验证其运行情况
注:本文重点讨论具备 XMX 的英特尔® GPU。在 CPU 或无 XMX 的 GPU(如 Meteor Lake)上的行为可能不同。
什么是动态量化?
动态量化通过在矩阵乘法(MatMul)运算前,将输入激活值(通常是 fp16)即时转换为 int8 来降低计算成本。
当模型权重已量化为 int4 或 int8 时,这种方法尤其高效。
在 OpenVINO™ 2025.2 中,量化沿着嵌入轴(最内层轴)进行。输入张量会被分组,每个分组的最小/最大值用于确定量化比例(scale)和零点(zero-point)。
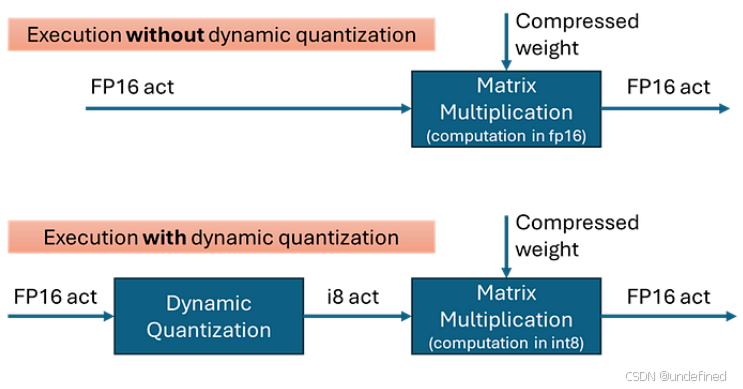
OpenVINO™ 2025.2 默认行为
在具备 XMX 的 GPU 上,OpenVINO™ 2025.2 默认启用动态量化。
-
逐 token 量化(每个 token 一个 scale)是默认模式,以最大化计算效率。
-
如果模型中包含合适的 MatMul 层,OpenVINO™ 会自动插入 dynamic_quantize 操作(输入过短除外)。
⛔ 何时会被禁用?
动态量化会基于输入 token 长度有条件地应用:
-
✅ 启用:token 长度 > 64
-
❌ 禁用:token 长度 ≤ 64
即使是长提示词,在生成阶段(第二个 token 开始)也可能因 KV 缓存导致行大小减小而跳过量化。
何时启用/禁用动态量化
动态量化在以下情况中最有效:
-
长输入序列处理(尤其是大语言模型,提示词 > 512 tokens)
性能提升可达数十个百分点。
-
矩阵乘法是推理瓶颈
如果模型的推理时间主要耗在 MatMul,动态量化可大幅加速计算。
以下情况效果可能不明显:
-
非常长的提示词但主要耗时在其他运算(如注意力层)
-
短输入(≤ 64 tokens)
默认禁用,计算节省有限且内存 I/O 占主导。
精度考虑
OpenVINO™的动态量化通常能保持较高精度,但在部分模型与应用中可能有轻微下降。
降低精度损失的方法:
-
使用较小的分组大小(如 256),提升精度但略微牺牲性能。
-
对精度极为敏感的任务,可直接禁用动态量化。
启用/禁用动态量化
✅ 启用(默认)
可通过运行时属性自定义:
ov::Core core;auto model = core.read_model("model.xml");ov::AnyMap config = {{"dynamic_quantization_group_size", 256}, // 自定义分组大小};auto compiled_model = core.compile_model(model, "GPU", config);
❌ 禁用
ov::AnyMap config = {{"dynamic_quantization_group_size",0} // 关闭量化};auto compiled_model = core.compile_model(model, "GPU", config);
如何验证动态量化是否启用
有两种方法:
1. 执行图
使用benchmark_app并开启执行图导出,查找是否存在 dynamic_quantize节点。
2. OpenCL 拦截层
追踪实际的 GPU kernel 调用日志或 device_performance_timing,若执行了会看到 dynamic_quantize。
工作原理
启用时,OpenVINO™会在图优化阶段在 MatMul 之前插入 dynamic_quantize 节点,并在运行时根据条件执行:
-
token 长度 > 阈值 → 执行量化
-
token 长度 ≤ 阈值 → 跳过量化
-
若通过配置禁用,则不会插入该节点
实测示例
在英特尔® Battlemage B580 GPU(具备 XMX)上运行 Qwen3–8B INT4 模型,使用 prompt_lookup_decoding_lm.py 脚本:
-
短提示词(如“What is OpenVINO?”):提升不明显
-
长提示词(4K token 科幻文本):首 token 延迟降低约 10–20%
虽然视觉上差异不大,但这体现了框架的智能运行时优化能力与高效的 GPU 执行路径。
总结
OpenVINO™ 2025.2 中的动态量化是一种简单却高效的方法,可自动加速英特尔® GPU 上的 Transformer 推理。
在处理长提示词或对性能要求极高的模型时,这一功能值得充分利用。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 12
12 0
0- 0



 已为社区贡献327条内容
已为社区贡献327条内容

所有评论(0)