实战精选 | 一步安装,一步配置:用 vLLM + OpenVINO™ 轻松加速大语言模型推理
随着大语言模型的广泛应用,模型的计算需求大幅提升,带来推理时延高、资源消耗大等挑战。vLLM 作为高效的大模型推理框架,通过 OpenVINO™ 的优化,vLLM 用户不仅能够更高效地部署大模型,还能提升吞吐量和处理能力,从而在成本、性能和易用性上获得最佳平衡。
作者 | 武卓 博士 英特尔 OpenVINO™ 布道师
随着大语言模型的广泛应用,模型的计算需求大幅提升,带来推理时延高、资源消耗大等挑战。vLLM 作为高效的大模型推理框架,通过 OpenVINO™ 的优化,vLLM 用户不仅能够更高效地部署大模型,还能提升吞吐量和处理能力,从而在成本、性能和易用性上获得最佳平衡。这种优化对于需要快速响应和节省资源的云端或边缘推理应用尤为重要。目前,OpenVINO™ 最新版本 OpenVINO™ 2024.4 中已经支持与 vLLM 框架的集成,只需要一步安装,一步配置,就能够以零代码修改的方式,将 OpenVINO™ 作为推理后端,在运行 vLLM 对大语言模型的推理时获得推理加速。
vLLM 简介
vLLM 是由加州大学伯克利分校开发的开源框架,专门用于高效实现大语言模型(LLMs)的推理和部署。它具有以下优势:
-
高性能:相比 HuggingFace Transformers 库,vLLM 能提升多达24倍的吞吐量。
-
易于使用:无需对模型架构进行任何修改即可实现高性能推理。
-
低成本:vLLM 的出现使得大模型的部署更加经济实惠。
一步安装:搭建 vLLM + OpenVINO™ 阿里云ECS开发环境
下面我们以在阿里云的免费云服务器 ECS 上运行通义千问 Qwen2.5 模型为例,详细介绍如何通过简单的两步,轻松实现 OpenVINO™ 对 vLLM 大语言模型推理服务的加速。
在阿里云上申请免费的云服务器 ECS 资源,并选择 Ubuntu22.04 作为操作系统。
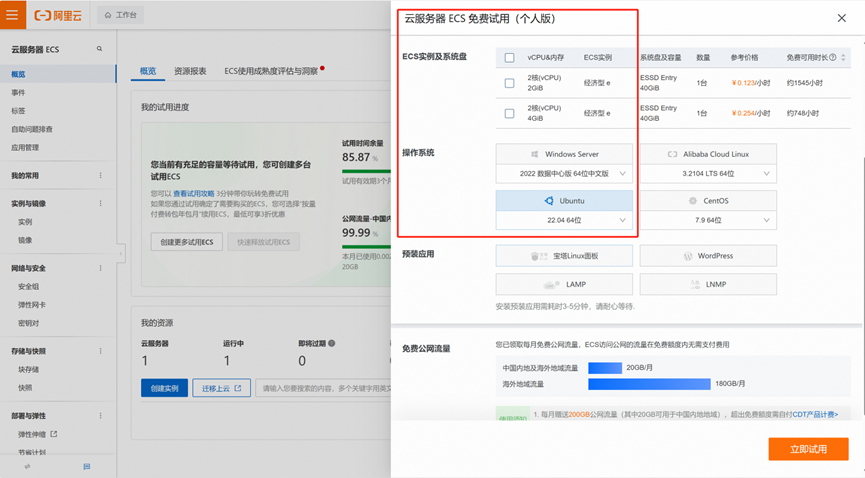
接着进行远程连接后,登录到终端操作界面。
请按照以下步骤配置开发环境:
1) 更新系统并安装 Python 3 及虚拟环境:
sudo apt-get update -ysudo apt-get install python3 python3.10-venv -y
2) 建立并激活 Python 虚拟环境:
python3 -m venv vllm_envsource vllm_env/bin/activate
3) 克隆 vLLM 代码仓库并安装依赖项:
git clone https://github.com/vllm-project/vllm.gitcd vllmpip install --upgrade pippip install -r requirements-build.txt --extra-index-url https://download.pytorch.org/whl/cpu
4) 安装 vLLM 的 OpenVINO™ 后端:
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/cpu" VLLM_TARGET_DEVICE=openvino python -m pip install -v .至此,环境搭建完毕。
魔搭社区大语言模型下载
接下来,去魔搭社区下载最新的通义千问2.5系列大语言模型,这里以 Qwen2.5-0.5B-Instruct 模型的下载为例。
模型下载地址为:
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
魔搭社区为开发者提供了多种模型下载的方式,这里我们以“命令行下载“方式为例。
首先用以下命令安装 modelscope:
pip install modelscope接着运行以下命令完成模型下载:
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct下载后的模型,默认存放在以下路径中:
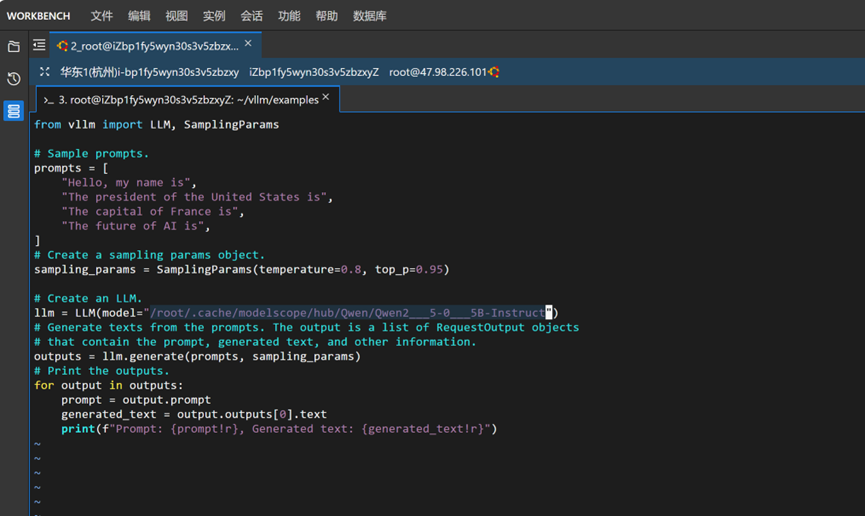
/root/.cache/modelscope/hub/Qwen/Qwen2___5-0___5B-Instruct本次运行的推理脚本,我们以 vllm 仓库中 examples 文件夹中的 offline_inference.py 推理脚本为例。由于 vLLM 默认的脚本是从 Hugging Face 平台上直接下载模型,而由于网络连接限制无法从该平台直接下载模型,因此我们采用上面的方式将模型从魔搭社区中下载下来,接下来使用以下命令,修改脚本中第14行,将原脚本中的模型名称“"facebook/opt-125m" “替换为下载后存放Qwen2.5模型的文件夹路径”
/root/.cache/modelscope/hub/Qwen/Qwen2___5-0___5B-Instruct“即可,效果如下图所示。
一步配置:配置并运行推理脚本
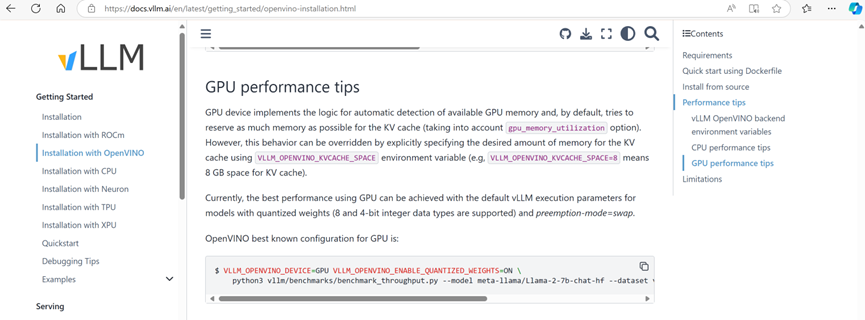
接下来,在运行推理脚本,完成 LLMs 推理之前,我们再针对 OpenVINO™ 作为推理后端,进行一些优化的配置。使用如下命令进行配置:
export VLLM_OPENVINO_KVCACHE_SPACE=1export VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON
这里,
-
VLLM_OPENVINO_KVCACHE_SPACE:用于指定键值缓存(KV Cache)的大小(例如,VLLM_OPENVINO_KVCACHE_SPACE=100 表示为 KV 缓存分配 100 GB 空间)。较大的设置可以让 vLLM 支持更多并发请求。由于本文运行在阿里云的免费 ECS 上空间有限,因此本次示例中我们将该值设置为1。实际使用中,该参数应根据用户的硬件配置和内存管理方式进行设置。
-
VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8:用于控制 KV 缓存的精度。默认情况下,会根据平台选择使用 FP16 或 BF16 精度。
-
VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS:用于启用模型加载阶段的 U8 权重压缩。默认情况下,权重压缩是关闭的。通过设置 VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON 来开启权重压缩。
为了优化 TPOT(Token Processing Over Time)和 TTFT(Time To First Token)性能,可以使用 vLLM 的分块预填充功能(--enable-chunked-prefill)。根据实验结果,推荐的批处理大小为 256(--max-num-batched-tokens=256)。
最后,让我们来看看 vLLM 使用 OpenVINO™ 后端运行大语言模型推理的效果,运行命令如下:
python offline_inference.py除了运行以上配置,可以利用 OpenVINO™ 在 CPU 上轻松实现 vLLM 对大语言模型推理加速外,也可以利用如下配置在英特尔集成显卡和独立显卡等 GPU 设备上获取 vLLM 对大语言模型推理加速
export VLLM_OPENVINO_DEVICE=GPUexport VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON
更多详细的信息,可以查询:
https://docs.vllm.ai/en/latest/getting_started/openvino-installation.html
结论
通过在 vLLM 中集成 OpenVINO™ 优化,用户能够显著提升大语言模型的推理效率,减少延迟并提高资源利用率。简单的配置步骤即可实现推理加速,使得在阿里云等平台上大规模并发请求的处理变得更加高效和经济。OpenVINO™ 的优化让用户在保持高性能的同时降低部署成本,为AI模型的实时应用和扩展提供了强有力的支持。
更多资源
-
OpenVINO™ 文档
https://docs.openvino.ai/2024/index.html
-
OpenVINO™ AI解决案例和演示
https://github.com/openvinotoolkit/openvino_build_deploy
-
反馈意见及上报问题
https://github.com/login?return_to=https%3A%2F%2Fgithub.com%2Fopenvinotoolkit%2Fopenvino%2Fissues%2Fnew%2Fchoose
通知及免责声明
性能因使用情况、配置和其他因素而异。如需了解详情,请访问网址:
https://edc.intel.com/content/www/us/en/products/performance/benchmarks/overview/
性能结果基于截至配置中显示的日期的测试,可能无法反映所有公开可用的更新。有关配置详细信息,请参阅备份。没有任何产品或组件可以绝对安全。您的成本和结果可能会有所不同。英特尔技术可能需要支持的硬件、软件或服务激活。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 6
6 0
0- 0



 已为社区贡献315条内容
已为社区贡献315条内容

所有评论(0)