OPEA:为企业级生成式AI解决方案提供破局之道
在数字化与智能化激流涌动的今天,高速发展的生成式人工智能(Generative AI, GenAI)正以前所未有的力量重塑千行百业,为企业带来创新与发展机遇。但与此同时,复杂的技术方案、高昂的部署成本、专业的人才获取,以及可扩展性等方面的挑战也在阻碍企业进一步发挥生成式AI的潜能。
为助力企业跨越这些障碍,英特尔正积极通过开源的发展、开放生态的建设来为企业提供更多、更好、更易用的“一站式工具集合”。在KubeCon China 2025上,英特尔将以“Get more from your Cloud with Intel”为主题,推出多场技术分享,开设技术专区,重点展示企业AI开放平台(Open Platform for Enterprise AI ,简称OPEA)、开放式边缘平台(Open Edge Platform)等开源项目和最新成果,支持云原生与开源生态建设,助力开源、AI 与云原生社区的“跨界”合作迈向新高度。
这其中,英特尔携手Linux基金会共同推进的OPEA项目(https://opea.dev/),以创新的六个子项目(包括GenAIExamples、GenAIComps、GenAIInfra、GenAIEval、GenAIStudio以及Docs),通过模块化框架助力用户创建开放、健壮、多供应商且可灵活组合的企业级生成式AI解决方案,整合生态创新成果。更多详情,请参阅https://github.com/opea-project

OPEA平台的核心优势
模块化架构与灵活可扩展部署
在架构设计上,OPEA提供了一系列涵盖基础模型服务、数据处理与增强、应用专用服务等各方面的微服务模块,包括大语言模型服务(LLM)、嵌入服务(Embedding)、检索服务(Retrieval)、重排序服务(Reranking)以及数据准备服务(DataPrep)等。通过服务编排,多个微服务能整合为功能完整的MegaServices(如ChatQnA、DocSum),满足企业复杂业务场景的需求。
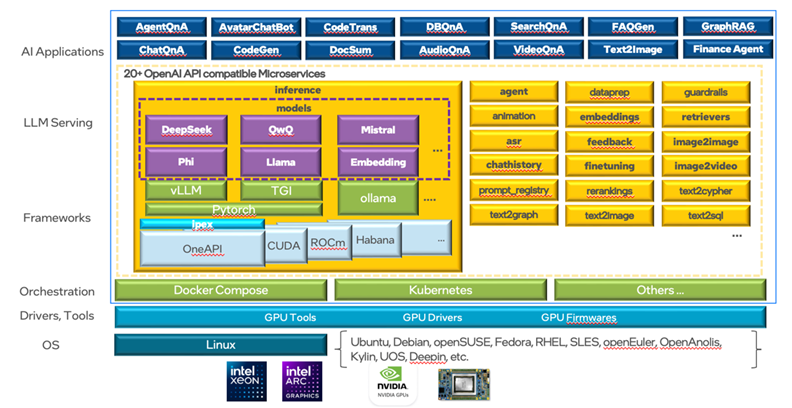
图1 OPEA架构概念图
在部署模式上,OPEA基于容器化和微服务化架构深度集成了云原生技术(位于GenAIInfra子项目),支持在 Docker 和 Kubernetes 环境中灵活部署。其不仅与AWS、Azure等主流云平台实现了集成,也可支持一键部署,可在公有云、私有云、混合云等多元云环境中轻松部署。借助强大的编排能力,实现应用自动扩展、负载均衡与高效管理,助力企业快速响应业务波动,降低运营成本。
此外,OPEA还提供了一个含评估工具和标准的代码仓,评估的维度包括性能、功能、可信度和企业级就绪程度四个方面,可帮助用户从不同维度对生成式AI解决方案进行全面评估。而OPEA内置的GenAIEval测试工具,能通过所收录的基准测试脚本,模拟不同应用场景(如ChatQnA等)、收集微服务延迟数据和系统资源利用率等信息,发现性能趋势和瓶颈。
硬件、操作系统与框架兼容性
PEA支持多种硬件平台,包括英特尔的CPU、Gaudi®️ AI加速器、锐炫™ 系列产品、AMD MI300加速器以及英伟达的GPU产品等,企业能灵活地在本地或云端选择硬件资源,而无需担心兼容问题或被特定厂商绑定。在操作系统支持上,OPEA可支持主流Linux内核版本,并在Ubuntu上得到了验证。未来OPEA还计划支持更多的Linux发行版和国产操作系统,这能帮助用户更方便地在不同操作系统环境中进行集成和部署,并与企业现有应用程序和系统无缝对接,形成统一的AI应用解决方案。
同时,OPEA支持多种推理模型(如DeepSeek、Hermes、Phi、Granite等)与框架(如vLLM、TGI、ollama等),用户可根据项目需求、熟悉程度、性能目标或预算予以选择,不再需要因框架限制而改变开发和优化思路或重构代码,专注于核心业务逻辑的实现。这既能帮助企业在性能和成本之间取得平衡,也降低了专业人才获取的困难度,并推动其AI应用与前沿AI 技术和框架的快速集成。
开源、开放与广泛的协作生态
OPEA采用Apache开源协议,代码完全开放,企业可以自由使用、修改并基于OPEA构建自己的产品。这种开放性不仅增强了透明度,还促进了全球开发者社区的协作与创新。
自项目启动以来,OPEA已吸引超过50个社区合作伙伴参与,且不断有新的伙伴加入。除英特尔以外,社区还吸引了AMD、Anyscale、Cloudera、Domino Data Lab、Hugging Face、Red Hat、MariaDB以及VMware等50余家行业巨头共同参与。这些合作伙伴共同为OPEA的发展贡献代码、插件、参考实现和最佳实践,形成了开放、灵活、强大和繁荣的开源生态系统,用户可根据自身需求选择不同的服务提供商和模型组合,构建具备高度可控性的生成式AI解决方案。
于OPEA的生成式AI方案实战
火山引擎g4il云实例
火山引擎最新发布的第四代计算实例 g4il同步搭配推出了由火山引擎和英特尔合作开发的应用镜像 —— “开源大模型应用-知识库问答”(Ubuntu 24.04 with LLM Knowledge Base 64 bit),供用户体验基于 CPU 快速开发专属的知识库问答系统,在云上实现“算力+模型”的一站式部署。该镜像内置基于OPEA的检索增强生成 (RAG)大模型知识库应用,支持用户上传专业资料打造自己的专属AI知识库,分钟级即可完成大模型知识库的部署。
OPEA + Dify在英特尔锐炫™ 显卡上构建基于DeepSeek的RAG工作流
RAG工作流能通过动态知识整合与生成式AI的协同,解决传统AI方案在准确性、时效性和安全性上的瓶颈,推动企业知识资产的高效利用。得益于OPEA提供的LLM、Embedding和Rerank等微服务模块,搭配Dify(易上手的 LLM 应用开发平台),用户现在可以基于DeepSeek构建高质量的RAG工作流。
组合方案可基于低成本的英特尔锐炫™ 显卡进行本地化部署,在显著降低硬件成本的同时,实现了全流程数据的本地化处理与隐私可控。而OPEA对DeepSeek模型的适配与优化,也让方案能在英特尔锐炫™ 显卡环境下流畅运行。
在英特尔锐炫™ 显卡上构建由OPEA驱动的DocSum解决方案
DocSum解决方案旨在通过智能化技术帮助企业实现海量非结构化数据的快速摘要与知识沉淀,为企业决策提供信息依据。得益于OPEA提供的Whisper、vllm、llm-docsum和docsum-gradio-ui等微服务模块以及其它一系列优势,用户能轻松打造从知识库准备到智能问答的端到端完整流程,无需额外开发或集成其它工具即可快速推动完整系统方案的搭建。
目前,这一方案已被验证可在英特尔锐炫™ 显卡上实现本地化生产级服务的部署,在大幅降低硬件成本和资源消耗的同时,也满足了金融、制造等行业对数据的高安全性要求。
英特尔® 至强® 处理器+ 锐炫™ 显卡 + OPEA,构建全新一体机产品
支持DeepSeek、Qwen等国内主流大语言模型的一体机产品,正有望凭借其卓越的性能表现与部署便捷性,成为“AI普惠革命”的关键一环。由英特尔® 至强® 处理器 + 锐炫™ 显卡构建的一体机硬件基座,不仅带来了性能与价格的双重Buff,也能与OPEA深度联动,以一系列微服务以及扩展性、可靠性和灵活性优势,助力企业根据需求灵活地选择并组合功能模块,轻松构建复杂的AI应用,使企业级AI解决方案的构建就像“搭积木”一样简单。
英特尔锐炫™ 显卡 + OPEA,解锁边缘AI新潜能
随着AI技术向边缘场景的延伸,边缘AI也逐步成为新的增长点。OPEA与入门级GPU(如英特尔锐炫™ 显卡)的结合,为边缘AI应用提供了理想选择。这一组合不仅满足了边缘设备对功耗、体积和成本的严格要求,还能在本地快速完成推理任务,实现低延迟的实时响应。在工业物联网、智能家居和自动驾驶等领域,OPEA可助力企业构建更加高效、可靠的边缘AI解决方案,推动智能化转型。
此外,在助力企业更快实现AI落地的过程中,由英特尔发布的开放式边缘平台(Open Edge Platform)也在边缘AI潜能的发掘中承担起更重要的作用。作为一个模块化的开源平台,其提供了类似云计算的简便性,能有效简化边缘与AI应用所需的大规模开发、部署和管理工作,让独立软件开发商、解决方案构建商和操作系统供应商能有效集成软件组件,并借助英特尔最新的软件技术优化性能。
· 具备构建生产级多模态边缘AI应用的可组合组件,以及用于优化和部署模型的用户友好型工作流;
· 执行边缘设备及边缘节点软件的入门、配置与管理工作,以及大规模 AI 应用与集群的编排工作;
· 能够快速展示英特尔硬件及其战略技术合作伙伴在边缘 AI 方面的性能与特性。
更多的AI创新工具集合
除OPEA与开放式边缘平台之外,包括oneAPI 2025.0工具包与框架优化、AI Assistant Builder开源框架等英特尔AI创新工具集合也正成为各类企业级AI解决方案的强劲助力。一方面,oneAPI 2025.0 工具包与框架优化强化了对生成式AI的支持,在量化与推理等方面实现显著突破。例如:
· 面向PyTorch的优化,原生支持至强® 6处理器和酷睿™️ Ultra处理器,通过TorchInductor与oneAPI DPC++/C++编译器结合,提升模型编译效率;
· 实现TensorFlow与JAX集成;
· 在神经压缩器(Intel® Neural Compressor)中新增Transformer-like量化API。
另一方面,在Computex 2025上发布的AI Assistant Builder(GitHub公开测试版)能允许用户快速构建本地AI代理,并面向英特尔平台(如AI PC)开展了大量优化。核心优势包括:
· 低代码开发:帮助用户通过模块化组件实现AI功能集成,支持自然语言交互、多模态处理等场景。目前已有多个合作伙伴基于该框架实现智能会议助手、实时内容生成工具等创新应用的开发;
· 隐私保护:本地运行模式能避免数据外传,尤其适合企业级敏感场景(如医疗、金融)。
未来展望
自 2023年3月发布首个内部白皮书以来,OPEA发展迅猛,为企业级复杂AI工作流提供了高可扩展性与高可用性保障,从架构到服务能力上都拉满了“企业级可落地”的标准线。随着使用场景与用户需求的不断扩展,OPEA势必将进一步强化与合作伙伴的协同,通过更多前沿AI技术和微服务,如GraphRAG(图谱增强生成)的引入来拓展功能版图,提升企业AI解决方案的开发效率和应用成效。同时,OPEA也将不断优化现有架构,降低部署成本,提升系统易用性和可维护性,让AI技术惠及更多用户。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 17
17 0
0- 0



 已为社区贡献327条内容
已为社区贡献327条内容

所有评论(0)