表格、公式、印章识别太难?OpenVINO™ Day 0 支持 PaddleOCR-VL-1.5:端侧文档解析一键 SOTA
OpenVINO™ 已完成 PaddleOCR-VL-1.5 的 Day 0 适配,并在英特尔® 酷睿™ Ultra 3系列上部署端到端文档解析流水线。
作者:武卓
文档解析远不止“把字读出来”:真正难点是读懂复杂版面——表格要保结构、公式要保排版、图表要提信息,连印章这类弧形字在屏拍/倾斜/弯折时都很容易失真。今天发布的PaddleOCR-VL-1.5 正是为此而来:仅 0.9B 参数就在权威评测集 OmniDocBench v1.5 取得 94.5% 高精度,超越全球顶尖通用大模型与文档解析专用模型,登顶 SOTA;在自建 Real5-OmniDocBench 的扫描、弯折、屏拍、光照变化、倾斜等真实场景同样全面领先。更关键的是,它创新性支持文档元素“异形框/多边形”定位,在复杂采集下也能稳定返回更贴合的检测框;同时新增文本行定位/识别与印章识别,并强化古籍/生僻字、多语种表格等难点能力(含扩展藏语、孟加拉语),让文档解析从“能用”真正迈向“可上线、可规模化”。
今天,我们为端侧开发者带来一个好消息:
OpenVINO™ 已完成 PaddleOCR-VL-1.5 的 Day 0 适配,并在英特尔® 酷睿™ Ultra 3系列上部署端到端文档解析流水线。该流水线包含 PP-DocLayout(版面/区域检测)+ 视觉编码器 + LLM (如下图所示),并可将负载原生分解并加载到 酷睿™ Ultra 3处理器的CPU + iGPU + NPU 三类引擎上,让端侧部署既“跑得动”,也“跑得稳”。
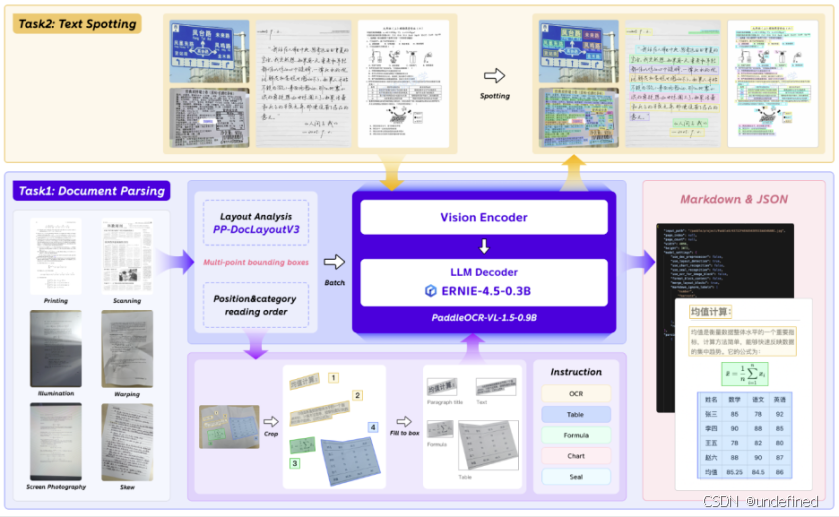
这次我们做的不只是“能跑”,而是把文档解析链路拆开,让每一段跑在更合适的引擎上:
-
PP-DocLayout(版面检测/区域定位):擅长卷积/检测类算子,适合在 iGPU / NPU 上加速(看你的部署策略与驱动能力)
-
视觉编码器(NaViT 风格动态分辨率视觉编码):对高分辨率文档更友好,视觉 token 化与编码阶段适合在 iGPU 上发挥吞吐优势
-
LLM(解析/生成结构化结果):可在 CPU 或 iGPU 上平衡吞吐与延迟;同时把更多“规则性强/可并行”的部分卸载出去,显著降低 CPU 压力,让系统更“顺滑”
这是 OpenVINO™ 在 英特尔® 酷睿™ Ultra 3系列平台上首次完成该类“端到端文档智能全链路”部署验证(包含版面模型 + 视觉编码器 + LLM 的组合链路)。
Step 1:环境搭建
git clone -b add_layout https://github.com/zhaohb/paddleocr_vl_ov.gitcd paddleocr_vl_ovpip install -e .
环境要求:Python 3.10+,OpenVINO 2025.4+。
Step 2:最短路径跑通
核心代码如下:
from paddleocr_vl_openvino.paddleocr_vl_pipeline import PaddleOCRVLpipeline = PaddleOCRVL(layout_model_path=pp_layout_model_path, # 提前下载好转换好的PP-DocLayoutV3vlm_model_path=paddleOCR-VLM_model_path, # 提前下载好转换好的 VLM# 设备策略(见 Step 3)vlm_device="AUTO",layout_device="AUTO",# 可选:版面模型精度(fp16更快/更省内存;fp32更准)layout_precision="fp16",# 默认就是“性能/体积/效果”比较均衡的一组配置vision_int8_quant=True,llm_int8_compress=True,llm_int8_quant=True,llm_int4_compress=False,)print("Starting recognition...")output = pipeline.predict("./test_images/paddleocr_vl_demo.png")for res in output:res.print()res.save_to_json(save_path="output")res.save_to_markdown(save_path="output")
Step 3:英特尔® 酷睿™ Ultra 3系列上的端侧部署闭环 的“CPU + iGPU + NPU”加载建议
这个 pipeline 允许你分别给 layout detection 与 VLM 配设备,所以很适合在 AI PC 上做“混合部署”。
-
一键让 OpenVINO™ 自己调度
-
vlm_device="AUTO",layout_device="AUTO"(让系统按可用硬件自动选择)。
-
-
显式“把版面检测扔给 NPU,把 VLM 交给 iGPU”
-
layout_device="NPU" + vlm_device="GPU"(CPU 负责整体编排与少量算子回退)。
-
Step 4:一键启动 Gradio 可视化 Demo(最适合 Day-0 展示)
仓库已内置 Gradio Web UI:上传文档图片 → 配置 pipeline → 输出 Markdown/JSON/可视化。
python client_app/main.py启动后访问 http://localhost:7860 。操作路径(仓库 README 的指引):
1. “Pipeline 配置” 初始化
2. “文档识别” 上传图片
3. 调参(threshold / max tokens 等)
4. 点“开始识别”查看 Markdown、JSON、可视化结果
最终的运行效果如下:
资源链接
-
PaddleOCR 官方站点 / API:https://www.paddleocr.com
-
PaddleOCR 开源仓库:https://github.com/PaddlePaddle/PaddleOCR
-
OpenVINO™ Notebooks仓库地址:https://github.com/openvinotoolkit/openvino_notebooks/pull/3263
到这里,你已经拿到了 PaddleOCR-VL-1.5 在英特尔® 酷睿™ Ultra 3系列上的端侧部署闭环:模型 Day 0 可用 → 端到端链路跑通 → 负载可拆分并加载到 CPU+iGPU+NPU。这意味着文档解析不再是“只能上云、只能堆资源”的能力,而是可以在 AI PC 上以更可控、更低占用、更可扩展的方式落地:从合同与票据抽取、到教育与小语种文档理解、再到古籍数字化与盖章核验,开发者都可以用 OpenVINO™ 把同一条推理链路工程化成服务/API/桌面应用,真正做到“端侧开箱即用”。
OpenVINO 小助手微信 : OpenVINO-China
如需咨询或交流相关信息,欢迎添加OpenVINO小助手微信,加入专属社群,与技术专家实时沟通互动。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 16
16 0
0- 0



 已为社区贡献322条内容
已为社区贡献322条内容

所有评论(0)