语音识别新标杆!OpenVINO™ 加速部署 Qwen3-ASR 实战
通义千问团队正式发布了 Qwen3-ASR 系列模型,包含 1.7B 和 0.6B 两个版本。作为 Qwen 语音家族的最新成员,它在多语言识别和处理复杂声学环境方面展现了卓越的性能。
作者:杨亦诚
近日,通义千问团队正式发布了 Qwen3-ASR 系列模型,包含 1.7B 和 0.6B 两个版本。作为 Qwen 语音家族的最新成员,它在多语言识别和处理复杂声学环境方面展现了卓越的性能。
模型特性
-
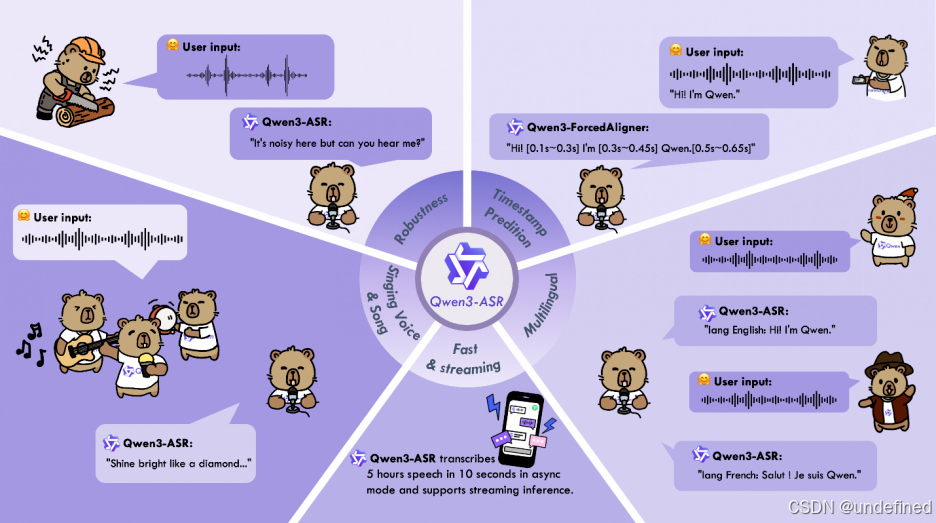
All-in-one(全能型):支持52 种语言和方言的语种识别(LID)与自动语音识别(ASR),包括 30 种语言、22 种中国方言以及来自多个国家和地区的英语口音。
-
Excellent and Fast(卓越且高效):在复杂声学环境和挑战性文本模式下保持高鲁棒性。1.7B 版本在开源 ASR 模型中达到了 SOTA 水平;而 0.6B 版本在保证精度的同时,在 128 并发下实现了2000 倍吞吐量,支持流式与离线统一推理及长音频转写。
-
核心优势:利用大规模语音训练数据和 Qwen3-Omni 基础模型的强大音频理解能力,在多项公开和内部基准测试中表现强劲。
本文将带你使用 Intel® OpenVINO™ 工具套件,通过原生转换方式在 Intel 平台上实现 Qwen3-ASR 的极致加速。
第一步:环境准备
为了确保与 Qwen3-ASR 架构兼容,我们需要安装特定版本的依赖库并克隆官方仓库。
# 1. 基础环境安装(要求 OpenVINO >= 2025.4)pip install -q --extra-index-url https://download.pytorch.org/whl/cpu \"torch==2.8.0" "torchaudio==2.8.0" "openvino>=2025.4.0" \"nncf" "gradio>=4.0" "huggingface_hub" "scipy" "qwen-asr"# 2. 克隆并安装 Qwen3-ASR 官方代码库git clone https://github.com/QwenLM/Qwen3-ASR.gitcd Qwen3-ASRgit checkout c17a131fe028b2e428b6e80a33d30bb4fa57b8dfpip install -q -e .
第二步:模型下载与转换
OpenVINO™ IR (Intermediate Representation)是OpenVINO™的中间表示格式,针对推理进行了深度优化。Qwen3-ASR模型包含4个子模块,需要分别转换:
1. Audio Conv Model (openvino_thinker_audio_model.xml): 音频特征提取的Conv2D前端
2. Audio Encoder Model (openvino_thinker_audio_encoder_model.xml): Transformer编码器层
3. Embedding Model (openvino_thinker_embedding_model.xml): 文本token嵌入层
4. Language Model (openvino_thinker_language_model.xml): 主LLM解码器,支持KV-cache
使用我们提供的helper函数进行转换:
from pathlib import Pathfrom qwen_3_asr_helper import convert_qwen3_asr_model# 配置参数model_id = "Qwen/Qwen3-ASR-0.6B"model_name = model_id.split("/")[-1]ov_model_dir = Path(f"{model_name}-OV")# 执行转换:将 PyTorch 模型导出为 OpenVINO IR 格式# 如果需要量化,可以在 quantization_config 中配置 NNCF 参数print(f"🚀 正在转换 Qwen3-ASR 模型...")convert_qwen3_asr_model(model_id=model_id,output_dir=ov_model_dir,quantization_config=None)print(f"✅ 转换完成,模型保存至: {ov_model_dir}")
这里你也可以将model_id通过以下方式替换成原始模型的本地路径进行转换:
convert_qwen3_asr_model(model_id=local_model_dir,output_dir=ov_model_dir,quantization_config=None, # 可选:设置 NNCF 配置进行 INT8 量化use_local_dir=True,# 可选:设置使用本地模型)
原始模型建议从魔搭社区下载获取:https://modelscope.cn/collections/Qwen/Qwen3-ASR
下载方式可以参考:https://modelscope.cn/docs/models/download
第三步:模型部署与推理
在部署阶段,我们使用 OVQwen3ASRModel 加载转换后的组件。该类封装了 OpenVINO™ 推理引擎,并针对 Intel 硬件(如 CPU/GPU/NPU)进行了优化。
1. 基础推理示例
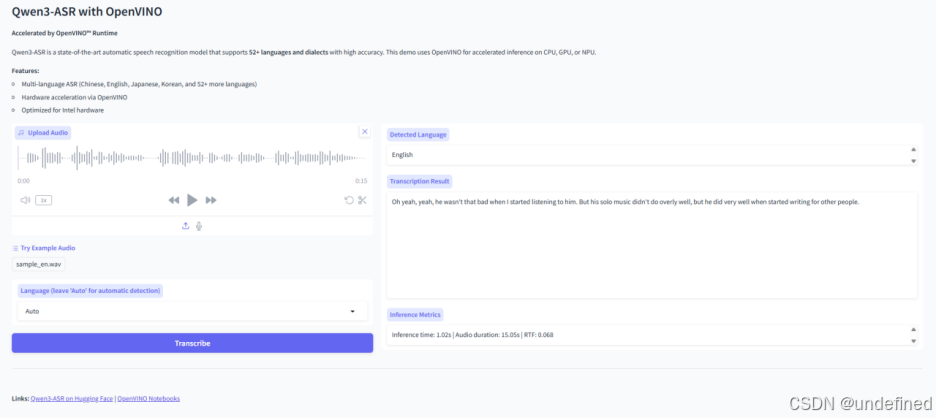
from qwen_3_asr_helper import OVQwen3ASRModel# 1. 初始化 OpenVINO 模型device = "CPU" # 可改为 "GPU"ov_model = OVQwen3ASRModel.from_pretrained(model_dir=str(ov_model_dir),device=device,max_inference_batch_size=32)# 2. 准备音频推理# 官方示例音频:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wavaudio_path = "asr_en.wav"print("🎙️ 正在进行语音识别...")results = ov_model.transcribe(audio=audio_path,language=None # 自动检测语种)# 3. 输出结果print(f"【检测语种】: {results[0].language}")print(f"【识别文本】: {results[0].text}")
输出示例:
Detected Language: English Transcription: Oh yeah, yeah, he wasn't that bad when I started listening to him. But his solo music didn't do overly well, but he did very well when started writing for other people.
2. 搭建交互式 Demo
借助 OpenVINO™ Notebooks 提供的辅助工具,几行代码即可启动一个支持语音识别功能的 Web 界面。
from gradio_helper import make_demo# 创建并启动 Gradio 演示界面demo = make_demo(ov_model, example_dir=None)demo.launch()
总结
通过 OpenVINO™ 的原生转换方案,我们成功地在 Intel 平台上部署了最新的 Qwen3-ASR 模型。这种方式不仅保留了官方模型的完整能力,更通过 OpenVINO™ 的图优化技术大幅提升了 0.6B 和 1.7B 模型的推理效率,为边缘侧的高性能语音应用提供了坚实基础。
想了解更多? 您可以访问 OpenVINO™ Notebooks 获取完整的代码示例。
参考资源
-
Qwen3-ASR官方仓库: https://github.com/QwenLM/Qwen3-ASR
-
OpenVINO™官方文档: https://docs.openvino.ai/
-
OpenVINO™ Notebooks: https://github.com/openvino-dev-samples/openvino_notebooks/blob/69b0f57df42a9b738988bfeffef53b0f1e100a64/notebooks/qwen3-asr/qwen3-asr.ipynb
-
Qwen3-ASR技术论文: arXiv:2601.21337
OpenVINO 小助手微信 : OpenVINO-China
如需咨询或交流相关信息,欢迎添加OpenVINO小助手微信,加入专属社群,与技术专家实时沟通互动。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 10
10 0
0- 0



 已为社区贡献320条内容
已为社区贡献320条内容

所有评论(0)