OpenVINO™ C++ 在哪吒开发板上推理 Transformer 模型
OpenVINO™ 是一个开源工具套件,用于对深度学习模型进行优化并在云端、边缘进行部署。它能在诸如生成式人工智能、视频、音频以及语言等各类应用场景中加快深度学习推理的速度,且支持来自 PyTorch、TensorFlow、ONNX 等热门框架的模型。实现模型的转换与优化,并在包括 Intel® 硬件及各种环境(本地、设备端、浏览器或者云端)中进行部署。
作者 | 王国强 苏州嘉树医疗科技有限公司 算法工程师
指导 | 颜国进 英特尔边缘计算创新大使
OpenVINO™ 介绍
OpenVINO™ 是一个开源工具套件,用于对深度学习模型进行优化并在云端、边缘进行部署。它能在诸如生成式人工智能、视频、音频以及语言等各类应用场景中加快深度学习推理的速度,且支持来自 PyTorch、TensorFlow、ONNX 等热门框架的模型。实现模型的转换与优化,并在包括 Intel® 硬件及各种环境(本地、设备端、浏览器或者云端)中进行部署。
图1-2 以深度学习为基础的AI技术在各行各业应用广泛
Ubuntu22.04 上的 OpenVINO™ 环境配置
OpenVINO™ 官方文档 https://docs.openvino.ai 有最新版本的安装教程,这里使用压缩包的方式安装,选择对应的 Ubuntu22 的版本:
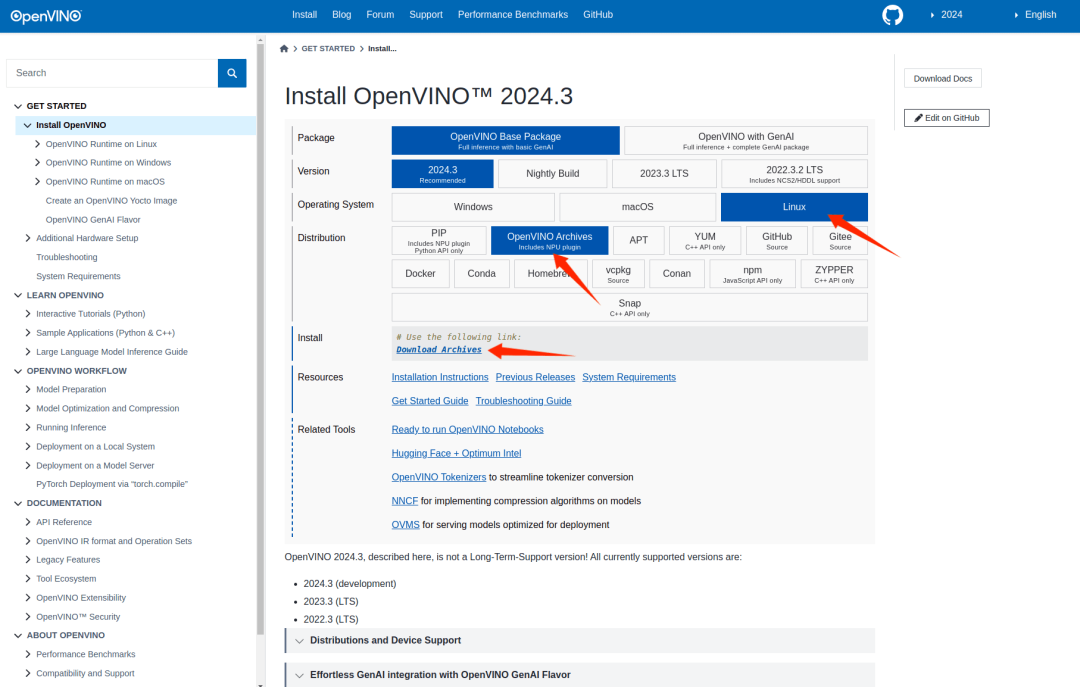
下载到哪吒开发板上后将压缩包解压:
tar -zxvf l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64.tgz进入解压目录,安装依赖:
cd l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64/
sudo -E ./install_dependencies/install_openvino_dependencies.sh然后配置环境变量:
source ./setupvars.sh这样 OpenVINO™ 的环境就配置好了,可以直接在 Intel CPU 上推理模型,如果需要在 Intel iGPU 上推理,还需要另外安装 OpenCL runtime packages,参考官方文档:
https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-gpu.html
这里使用 deb 包的方式安装,按照 Github
https://github.com/intel/compute-runtime
的说明下载7个 deb 包,然后 dpkg 安装:
sudo dpkg -i *.deb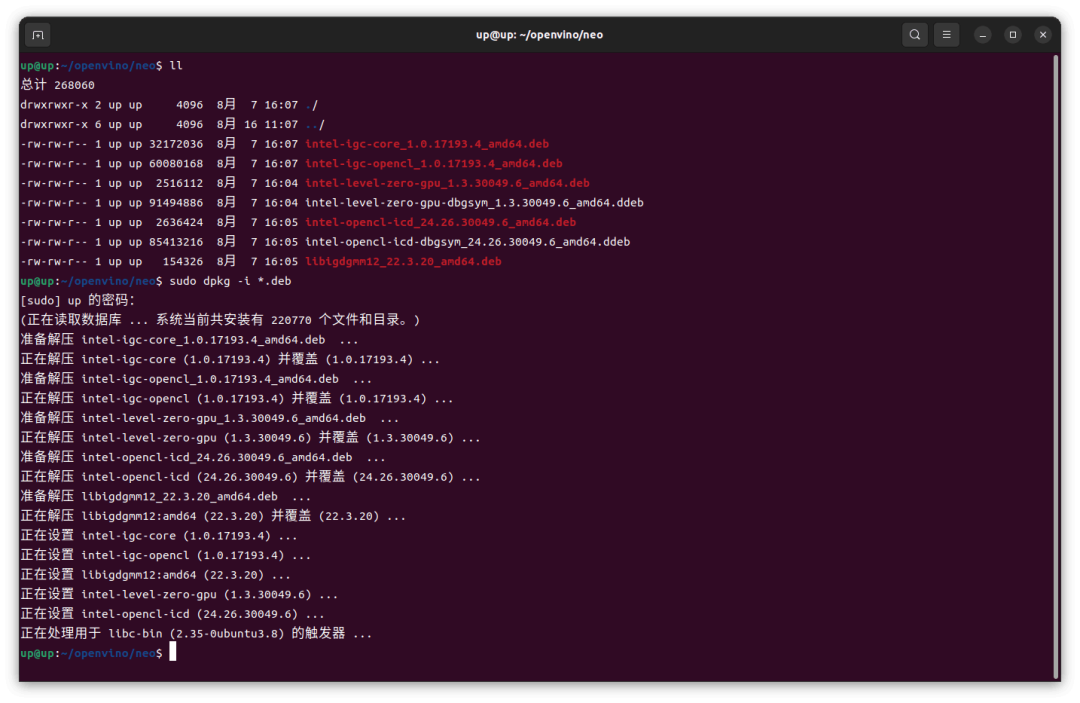
如果 dpkg 安装出现依赖报错,就需要先 apt 安装依赖,然后再 dpkg 安装7个 deb 包:
sudo apt install ocl-icd-libopencl1这样在哪吒开发板 Ubuntu22.04 上使用 Intel iGPU 进行 OpenVINO™ 推理的环境就配置完成了。
Transformer 模型推理
模型是一个基于 Transformer 结构的模型,训练后生成 ONNX 中间表示,OpenVINO™ 可以直接使用 ONNX 模型进行推理,也可以转为 OpenVINO™ IR 格式,转换命令如下:
ovc model.onnx默认会生成 FP16 的模型,如果精度有较大损失,可指定 compress_to_fp16 为 False 就不会进行 FP16 量化了:
ovc model.onnx --compress_to_fp16=False转换后将生成.xml和.bin两个文件,.xml文件描述了模型的结构,.bin文件包含了模型各层的参数。
推理代码如下:
#include <iostream>#include <fstream>#include <string>#include <sstream>#include <vector>#include <openvino.hpp>#include <filesystem>const int length = 300;void read_csv(const char* filepath, float* input){std::ifstream file(filepath);std::string line;if (file.is_open()){std::getline(file, line);for (int i = 0; i < 300; i++){std::getline(file, line);std::stringstream ss(line);std::string field;if (std::getline(ss, field, ',')){if (std::getline(ss, field, ',')){input[i] = std::stof(field);}}}file.close();}float maxVal = *std::max_element(input, input + 300);for (int i = 0; i < 300; i++){input[i] /= maxVal;}}std::vector<float> softmax(std::vector<float> input){std::vector<float> output(input.size());float sum = 0;for (int i = 0; i < input.size(); i++){output[i] = exp(input[i]);sum += output[i];}for (int i = 0; i < input.size(); i++){output[i] /= sum;}return output;}void warmup(ov::InferRequest request){std::vector<float> inputData(length);memcpy(request.get_input_tensor().data<float>(), inputData.data(), length * sizeof(float));request.infer();}int main(){const char* modelFile = "/home/up/openvino/AutoInjector_Transformer/AutoInjector_Transformer/2024-07-17-17-28-00_best_model.xml";const char* dirpath = "/home/up/openvino/AutoInjector_Transformer/AutoInjector_Transformer/data";const char* device = "GPU";std::vector<float> inputs(length);std::vector<float> outputs(length * 4);ov::Core core;// Load Modelstd::cout << "Loading Model" << std::endl;auto start_load_model = std::chrono::high_resolution_clock::now();auto model = core.read_model(modelFile);auto compiled_model = core.compile_model(model, device);ov::InferRequest request = compiled_model.create_infer_request();std::cout << "Model Loaded, " << "time: " << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start_load_model).count() << "ms" << std::endl;request.get_input_tensor().set_shape(std::vector<size_t>{1, length});// Warmupwarmup(request);for (auto& filename : std::filesystem::directory_iterator(dirpath)){std::string pathObj = filename.path().string();const char* filepath = pathObj.c_str();std::cout << "Current File: " << filepath << std::endl;// Read CSVauto start = std::chrono::high_resolution_clock::now();read_csv(filepath, inputs.data());memcpy(request.get_input_tensor().data<float>(), inputs.data(), length * sizeof(float));// Inferrequest.infer();// Get Output Datamemcpy(outputs.data(), request.get_output_tensor().data<float>(), length * sizeof(float) * 4);// Softmaxstd::vector<float> softmax_results(length);std::vector<float> temp(4);std::vector<float> softmax_tmp(4);for (int i = 0; i < length; i++){for (int j = 0; j < 4; j++){temp[j] = outputs[j * length + i];}softmax_tmp = softmax(temp);auto maxVal = std::max_element(softmax_tmp.begin(), softmax_tmp.end());auto maxIndex = std::distance(softmax_tmp.begin(), maxVal);softmax_results[i] = maxIndex;}std::cout << "Infer time: " << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count() << "ms" << std::endl;// Print outputsfor (int i = 0; i < length; i++){std::cout << softmax_results[i] << " ";}}return 0;}
使用 cmake 进行构建,在 CMakeLists.txt 中指定变量 ${OpenVino_ROOT} 为前面解压的 OpenVINO 压缩包路径:
cmake_minimum_required(VERSION 3.10.0)project(AutoInjector_Transformer)set(CMAKE_CXX_STANDARD 20)set(CMAKE_CXX_STANDARD_REQUIRED ON)set(OpenVino_ROOT /home/up/openvino/l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64/runtime)set(OpenVINO_DIR ${OpenVino_ROOT}/cmake)find_package(OpenVINO REQUIRED)include_directories(${OpenVino_ROOT}/include${OpenVino_ROOT}/include/openvino)link_directories(${OpenVino_ROOT}/lib${OpenVino_ROOT}/lib/intel64)add_executable(AutoInjector_Transformer AutoInjector_Transformer.cpp)target_link_libraries(AutoInjector_Transformer openvino)
然后 cmake 构建项目:
mkdir build && cd buildcmake ..make
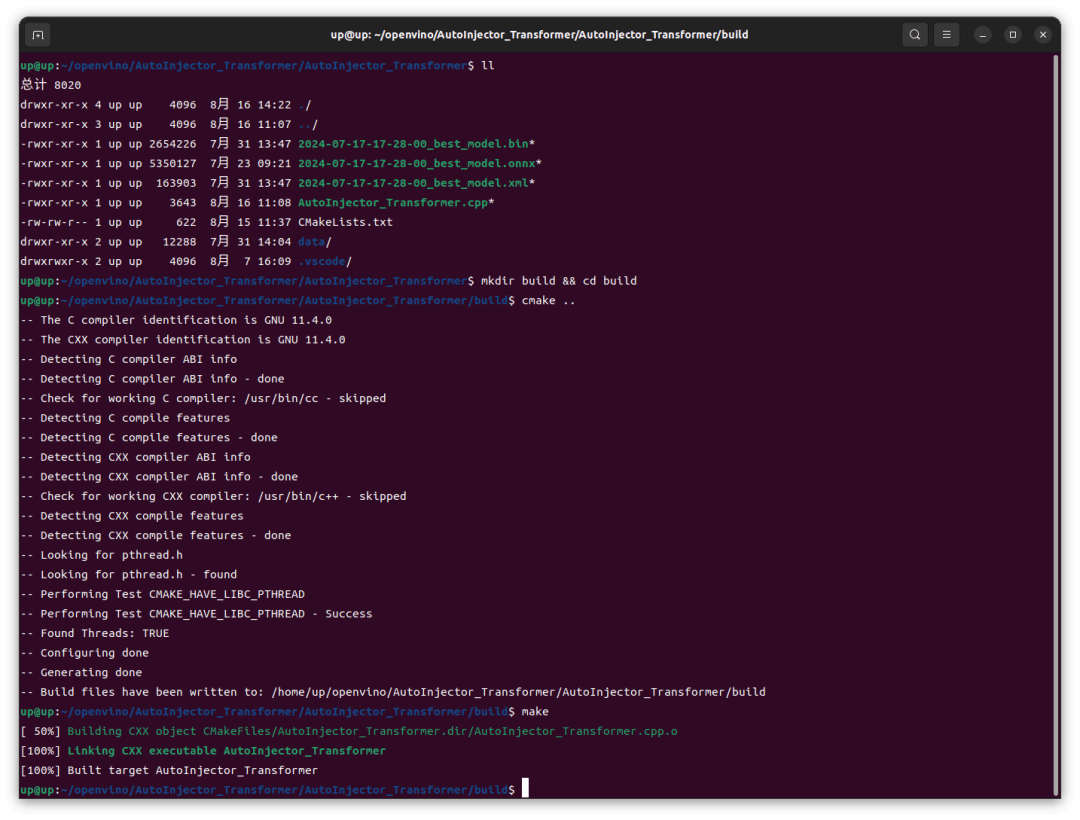
然后运行生成的可执行文件:
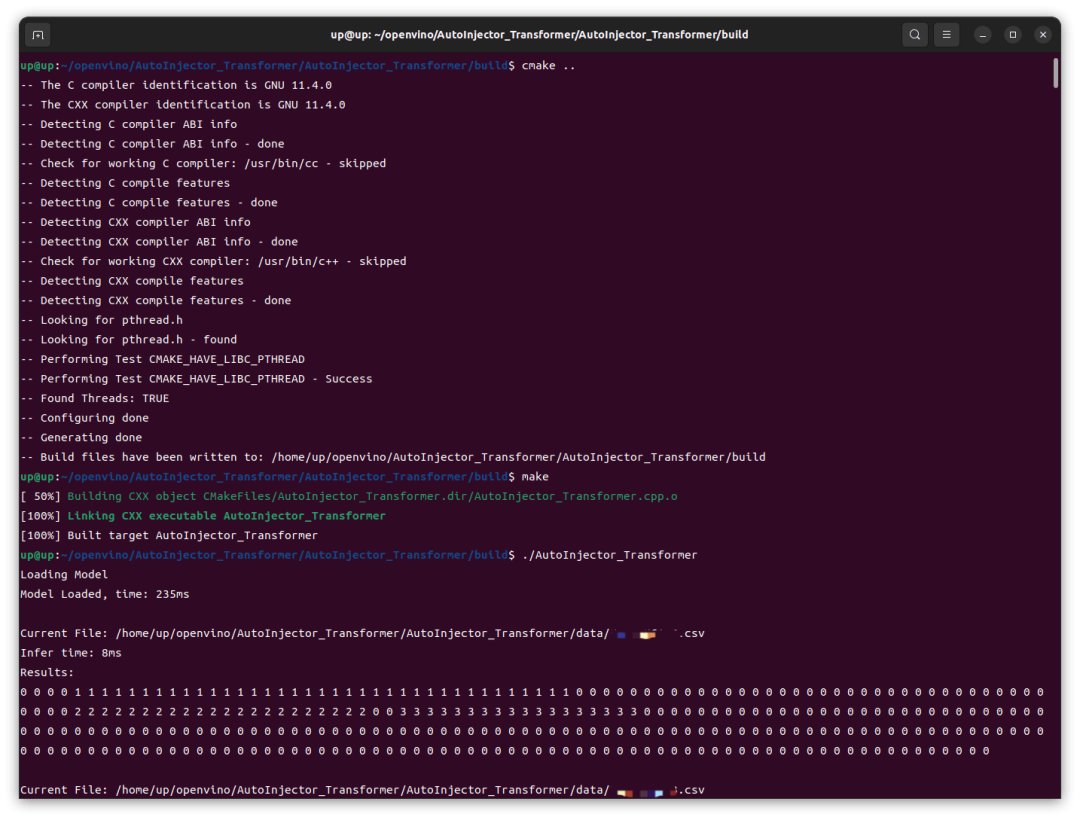
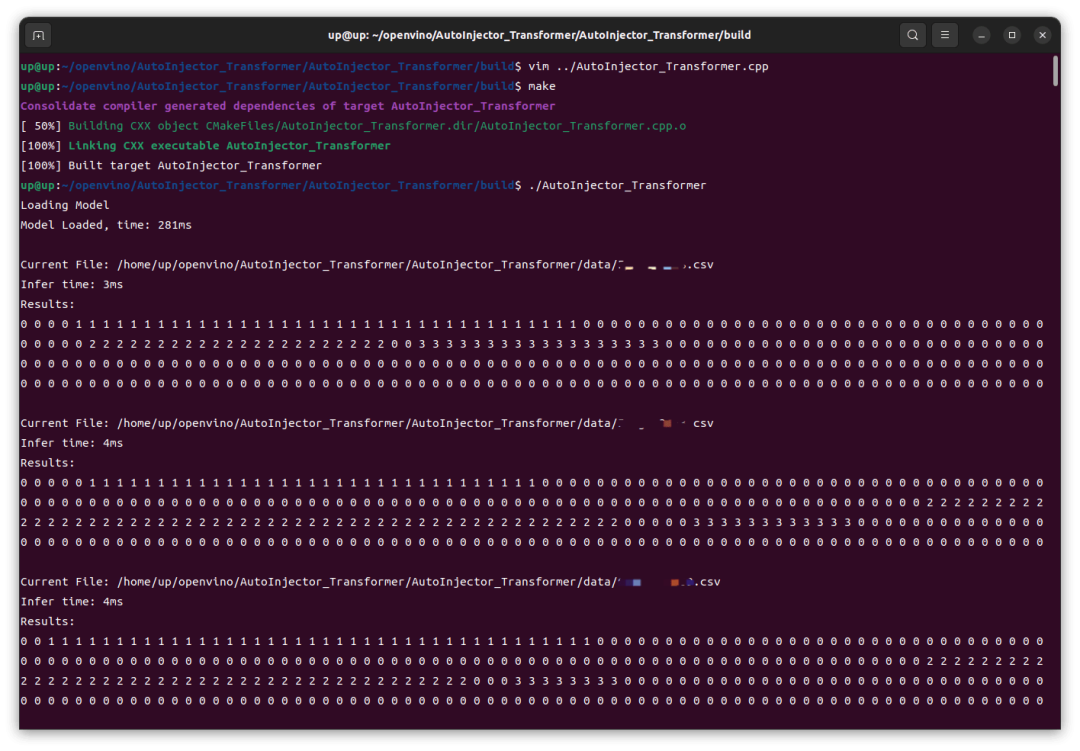
可以看到,在 Intel iGPU 上的推理速度还是很快的,前几次推理稍慢,8ms,后续基本稳定在 4ms,这跟我之前在 RTX4060 GPU 上用 TensorRT 推理并没有慢多少。然后我这里修改了代码改为 CPU 运行,重新编译、运行,结果在 Intel CPU 上的速度还要更快一点。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐



 5
5 0
0- 0



 已为社区贡献301条内容
已为社区贡献301条内容

所有评论(0)