OPEA驱动的Deepseek解决方案:助力企业智能化转型
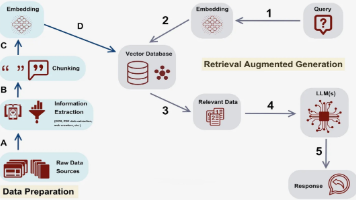
RAG通过“检索-生成”双引擎架构,在回答问题时,先从企业私有知识库、数据库或实时数据源中检索相关片段,再基于检索结果生成精准回答。这一机制突破了大模型固有的知识静态性局限,确保输出内容始终与企业的最新数据、内部规则保持一致。
在智能化转型中,企业级用户的核心矛盾在于通用性与个性化之间的平衡。大语言模型如Deepseek具备强大的通用能力,能够处理广泛的任务和场景,但企业的实际需求往往涉及私有化知识、实时数据以及特定的垂直场景。这些需求无法完全依赖通用模型来满足。 这些问题促使了RAG (Retrieval-Augmented Generation,知识检索增强生成) 技术的诞生。RAG通过“检索-生成”双引擎架构,在回答问题时,先从企业私有知识库、数据库或实时数据源中检索相关片段,再基于检索结果生成精准回答。这一机制突破了大模型固有的知识静态性局限,确保输出内容始终与企业的最新数据、内部规则保持一致。 由此可见,DeepSeek与RAG的结合,为企业提供了一套从数据整合到智能决策的闭环解决方案,成为推动企业智能化转型的核心引擎。
基于OPEA平台的RAG应用
在Linux基金会支持的OPEA (Open Platform for Enterprise AI) 项目中,专注于为企业提供开放和可扩展的AI平台。OPEA为开发者提供了多个支持RAG应用的功能和服务,帮助企业更好地集成知识检索和生成模型。
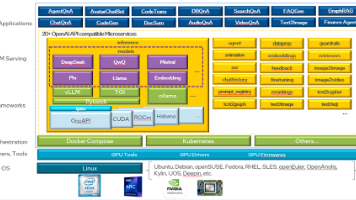
在OPEA平台中,实现了上文所述的多个与RAG相关的微服务, 例如:

OPEA提供了诸多优势,帮助企业实现高效、灵活的AI应用部署。
1. 显著的硬件平台无关性:支持Intel CPU、Gaudi、ARC、AMD MI300等多种平台, 使企业能够灵活选择硬件资源进行优化,无需担心兼容问题或受特定厂商限制。
2. 操作系统无关性:它支持主流的Linux内核版本,并在Ubuntu上经过了验证,未来还计划支持更多的Linux发行版和国产操作系统。
3. 推理框架无关性:支持包括vllm在内的多种主流推理框架。
4. 云原生:通过容器化和微服务化的架构,提供了极高的可扩展性、可靠性和灵活性。
5. 开源开放特性:OPEA采用Apache开源协议,代码完全开放,企业可以自由使用、修改甚至基于OPEA构建自己的商业产品。
实战:搭建基于OPEA+Deepseek的
聊天机器人(ChatQnA)应用
针对企业低成本部署大模型的核心诉求,本文将以DeepSeek-R1-Distill-Qwen-32B轻量化模型为基座,实战演示如何通过4路英特尔®锐炫™A770显卡(总成本<6万元)构建符合生产要求的基于OPEA的ChatQnA应用。手把手教大家部署、配置以及使用这一方案。
硬件和驱动安装配置
本方案的软硬件配置如下。关于硬件环境配置和驱动安装,可以参见上一篇文章的第一章节“软硬件安装配置与初始化”。

安装软件依赖
安装docker和docker compose: 参考docker官网安装步骤来安装或者升级系统中的docker和docker compose
安装依赖:
# 安装 pippython3 -m pip install --upgrade pip# 安装 Modelscopepip install modelscope
模型预下载
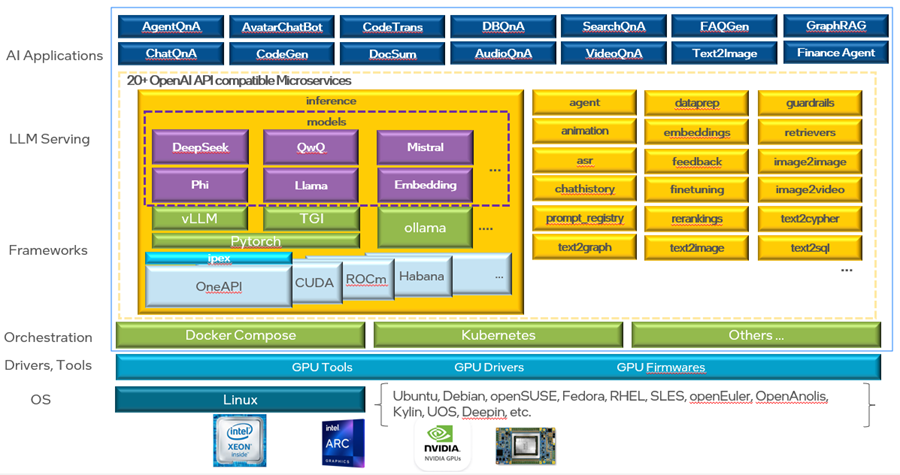
如下图所示,ChatQnA 的使用案例涉及多个模型,这些模型将用于 vllm(vLLM推理服务)、embedding(嵌入服务)、dataprep(知识库准备服务)和 reranking(重排服务)。为避免服务启动时间过长或者网络原因导致的下载失败,请按照以下步骤将模型预先下载到本地。

执行以下命令,保存预下载模型
# 创建 opea/ 目录来保存预下载模型
mkdir -p opea/
cd opea
# 下载Deepseek大语言模型
mkdir -p ./data/DeepSeek-R1-Distill-Qwen-32B
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --local_dir ./data/DeepSeek-R1-Distill-Qwen-32B
# 下载用于嵌入服务的模型
mkdir ./data/BAAI-bge-base-en-v1.5
modelscope download --model BAAI/bge-base-en-v1.5 --local_dir ./data/BAAI-bge-base-en-v1.5
# 下载用于重排服务的模型
mkdir ./data/BAAI--bge-reranker-base
modelscope download --model BAAI/bge-reranker-base --local_dir ./data/BAAI-bge-reranker-base
# 下载用于知识库准备服务的模型
mkdir ./data/unstructuredio/yolo_x_layout
modelscope download --model AI-ModelScope/yolo_x_layout --local_dir ./data/unstructuredio/yolo_x_layout安装ChatQnA服务组件
设置公共环境变量
在代理环境中,还需要设置与代理相关的环境变量
export host_ip=localhostexport TAG="1.2"export http_proxy=<your_http_proxy>export https_proxy=<your_https_proxy>export no_proxy=<your_no_proxy>
安装知识库准备服务
-
设置环境变量
export INDEX_NAME="rag-redis"export EMBEDDING_MODEL_ID="BAAI/bge-base-en-v1.5"
-
将下面docker compose文件保存成compose-dataprep.yaml 放到opea目录下
services:
redis-vector-db:
image: redis/redis-stack:7.2.0-v9
container_name: redis-vector-db
ports:
- "6379:6379"
- "8001:8001"
dataprep-redis-service:
image: ${REGISTRY:-opea}/dataprep:${TAG:-latest}
container_name: dataprep-redis-server
depends_on:
- redis-vector-db
- tei-embedding-service
ports:
- "6007:5000"
environment:
no_proxy: ${no_proxy}
http_proxy: ${http_proxy}
https_proxy: ${https_proxy}
REDIS_URL: redis://redis-vector-db:6379
REDIS_HOST: redis-vector-db
INDEX_NAME: ${INDEX_NAME}
TEI_EMBEDDING_ENDPOINT: http://tei-embedding-service:80
HUGGINGFACEHUB_API_TOKEN: ${HUGGINGFACEHUB_API_TOKEN}
volumes:
- "./data/unstructuredio/yolo_x_layout:/home/user/comps/dataprep/src/unstructuredio/yolo_x_layout"
tei-embedding-service:
image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.5
container_name: tei-embedding-server
ports:
- "6006:80"
volumes:
- "./data:/data"
shm_size: 1g
environment:
no_proxy: ${no_proxy}
http_proxy: ${http_proxy}
https_proxy: ${https_proxy}
command: --model-id ${EMBEDDING_MODEL_ID} --auto-truncate
networks:
default:
driver: bridge-
启动知识库准备服务
docker compose -f compose-dataprep.yaml up -d 安装检索服务
-
设置环境变量
export INDEX_NAME="rag-redis"
export LOGFLAG=false-
将下面docker compose文件保存成compose-retriever.yaml 放到opea目录下
services:
retriever:
image: ${REGISTRY:-opea}/retriever:${TAG:-latest}
container_name: retriever-redis-server
ports:
- "7000:7000"
ipc: host
environment:
no_proxy: ${no_proxy}
http_proxy: ${http_proxy}
https_proxy: ${https_proxy}
REDIS_URL: redis://redis-vector-db:6379
REDIS_HOST: redis-vector-db
INDEX_NAME: ${INDEX_NAME}
TEI_EMBEDDING_ENDPOINT: http://tei-embedding-service:80
HUGGINGFACEHUB_API_TOKEN: ${HUGGINGFACEHUB_API_TOKEN}
LOGFLAG: ${LOGFLAG}
RETRIEVER_COMPONENT_NAME: "OPEA_RETRIEVER_REDIS"
restart: unless-stopped
networks:
default:
driver: bridge-
启动检索服务
docker compose -f compose-retriever.yaml up -d安装重排服务
-
设置环境变量
export RERANK_MODEL_ID="BAAI/bge-reranker-base"-
将下面docker compose文件保存成compose-rerank.yaml 放到opea目录下
services:
tei-reranking-service:
image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.5
container_name: tei-reranking-server
ports:
- "8808:80"
volumes:
- "./data:/data"
shm_size: 1g
environment:
no_proxy: ${no_proxy}
http_proxy: ${http_proxy}
https_proxy: ${https_proxy}
HUGGINGFACEHUB_API_TOKEN: ${HUGGINGFACEHUB_API_TOKEN}
HF_HUB_DISABLE_PROGRESS_BARS: 1
HF_HUB_ENABLE_HF_TRANSFER: 0
command: --model-id ${RERANK_MODEL_ID} --auto-truncate
networks:
default:
driver: bridge-
启动重排服务
docker compose -f compose-rerank.yaml up -d安装基于ipex-llm的LLM推理服务
-
设置环境变量
export LOGFLAG=falseexport SHM_SIZE=16export DTYPE="float16"export QUANTIZATION="fp8"export MAX_MODEL_LEN="2048"export MAX_NUM_BATCHED_TOKENS="4000"export MAX_NUM_SEQS="256"export TENSOR_PARALLEL_SIZE="4"export GPU_AFFINITY="0,1,2,3"export LLM_MODEL_ID="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"export LLM_MODEL_LOCAL_PATH="/data/DeepSeek-R1-Distill-Qwen-32B"
-
将下面docker compose文件保存成compose-vllm.yaml 放到opea目录下
services:
vllm-service:
image: intelanalytics/ipex-llm-serving-xpu:2.2.0-b14
container_name: vllm-service
ports:
- "9009:80"
group_add:
- "video"
privileged: true
devices:
- "/dev/dri:/dev/dri"
volumes:
- "./data:/data"
shm_size: ${SHM_SIZE:-8g}
environment:
no_proxy: ${no_proxy}
http_proxy: ${http_proxy}
https_proxy: ${https_proxy}
HUGGINGFACE_HUB_CACHE: "/data"
LLM_MODEL_ID: ${LLM_MODEL_ID}
LLM_MODEL_LOCAL_PATH: ${LLM_MODEL_LOCAL_PATH}
VLLM_TORCH_PROFILER_DIR: "/mnt"
DTYPE: ${DTYPE:-float16}
QUANTIZATION: ${QUANTIZATION:-fp8}
MAX_MODEL_LEN: ${MAX_MODEL_LEN:-2048}
MAX_NUM_BATCHED_TOKENS: ${MAX_NUM_BATCHED_TOKENS:-4000}
MAX_NUM_SEQS: ${MAX_NUM_SEQS:-256}
TENSOR_PARALLEL_SIZE: ${TENSOR_PARALLEL_SIZE:-1}
healthcheck:
test: ["CMD-SHELL", "curl -f http://$host_ip:9009/health || exit 1"]
interval: 10s
timeout: 10s
retries: 100
entrypoint: /bin/bash -c "export CCL_WORKER_COUNT=2 &&
export SYCL_CACHE_PERSISTENT=1 &&
export FI_PROVIDER=shm &&
export CCL_ATL_TRANSPORT=ofi &&
export CCL_ZE_IPC_EXCHANGE=sockets &&
export CCL_ATL_SHM=1 &&
export USE_XETLA=OFF &&
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=2 &&
export TORCH_LLM_ALLREDUCE=0 &&
export CCL_SAME_STREAM=1 &&
export CCL_BLOCKING_WAIT=0 &&
export ZE_AFFINITY_MASK=$GPU_AFFINITY &&
python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
--served-model-name $LLM_MODEL_ID \
--model $LLM_MODEL_LOCAL_PATH \
--port 80 \
--trust-remote-code \
--block-size 8 \
--gpu-memory-utilization 0.95 \
--device xpu \
--dtype $DTYPE \
--enforce-eager \
--load-in-low-bit $QUANTIZATION \
--max-model-len $MAX_MODEL_LEN \
--max-num-batched-tokens $MAX_NUM_BATCHED_TOKENS \
--max-num-seqs $MAX_NUM_SEQS \
--tensor-parallel-size $TENSOR_PARALLEL_SIZE \
--disable-async-output-proc \
--distributed-executor-backend ray"
networks:
default:
driver: bridge-
启动重排服务
docker compose -f compose-vllm.yaml up -d安装问答界面
-
设置环境变量
export LOGFLAG=falseexport BACKEND_SERVICE_ENDPOINT="/v1/chatqna"export DATAPREP_SERVICE_ENDPOINT="/v1/dataprep/ingest"export NGINX_PORT="8000"
-
将下面docker compose文件保存成compose-ui.yaml 放到opea目录下
services:
chatqna-xeon-backend-server:
image: ${REGISTRY:-opea}/chatqna:${TAG:-latest}
container_name: chatqna-xeon-backend-server
ports:
- "8888:8888"
environment:
- no_proxy=${no_proxy}
- https_proxy=${https_proxy}
- http_proxy=${http_proxy}
- MEGA_SERVICE_HOST_IP=chatqna-xeon-backend-server
- EMBEDDING_SERVER_HOST_IP=tei-embedding-service
- EMBEDDING_SERVER_PORT=${EMBEDDING_SERVER_PORT:-80}
- RETRIEVER_SERVICE_HOST_IP=retriever
- RERANK_SERVER_HOST_IP=tei-reranking-service
- RERANK_SERVER_PORT=${RERANK_SERVER_PORT:-80}
- LLM_SERVER_HOST_IP=vllm-service
- LLM_SERVER_PORT=${LLM_SERVER_PORT:-80}
- LLM_MODEL=${LLM_MODEL_ID}
- LOGFLAG=${LOGFLAG}
ipc: host
restart: always
chatqna-xeon-ui-server:
image: opea/chatqna-conversation-ui:${TAG:-latest}
container_name: chatqna-xeon-conversation-ui-server
environment:
- APP_BACKEND_SERVICE_ENDPOINT=${BACKEND_SERVICE_ENDPOINT}
- APP_DATA_PREP_SERVICE_URL=${DATAPREP_SERVICE_ENDPOINT}
- no_proxy=${no_proxy}
- https_proxy=${https_proxy}
- http_proxy=${http_proxy}
ports:
- "5174:80"
depends_on:
- chatqna-xeon-backend-server
ipc: host
restart: always
chatqna-xeon-nginx-server:
image: ${REGISTRY:-opea}/nginx:${TAG:-latest}
container_name: chatqna-xeon-nginx-server
depends_on:
- chatqna-xeon-backend-server
- chatqna-xeon-ui-server
ports:
- "${NGINX_PORT:-80}:80"
environment:
- no_proxy=${no_proxy}
- https_proxy=${https_proxy}
- http_proxy=${http_proxy}
- FRONTEND_SERVICE_IP=chatqna-xeon-ui-server
- FRONTEND_SERVICE_PORT=80
- BACKEND_SERVICE_NAME=chatqna
- BACKEND_SERVICE_IP=chatqna-xeon-backend-server
- BACKEND_SERVICE_PORT=8888
- DATAPREP_SERVICE_IP=dataprep-redis-service
- DATAPREP_SERVICE_PORT=5000
ipc: host
restart: always
networks:
default:
driver: bridge-
启动重排服务
docker compose -f compose-ui.yaml up -d体验ChatQnA服务
-
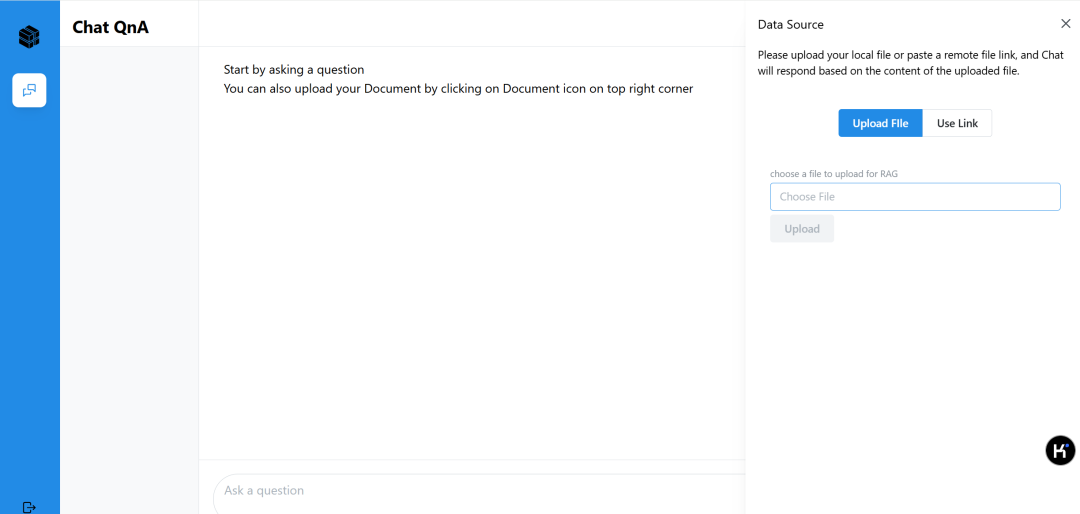
在浏览器打开http://localhost:8000,访问基于OPEA的ChatQnA聊天机器人。
2.点击右上角的上传按钮,选择一个或者多个私有知识库提交。目前支持pdf, txt,docx等文件格式。
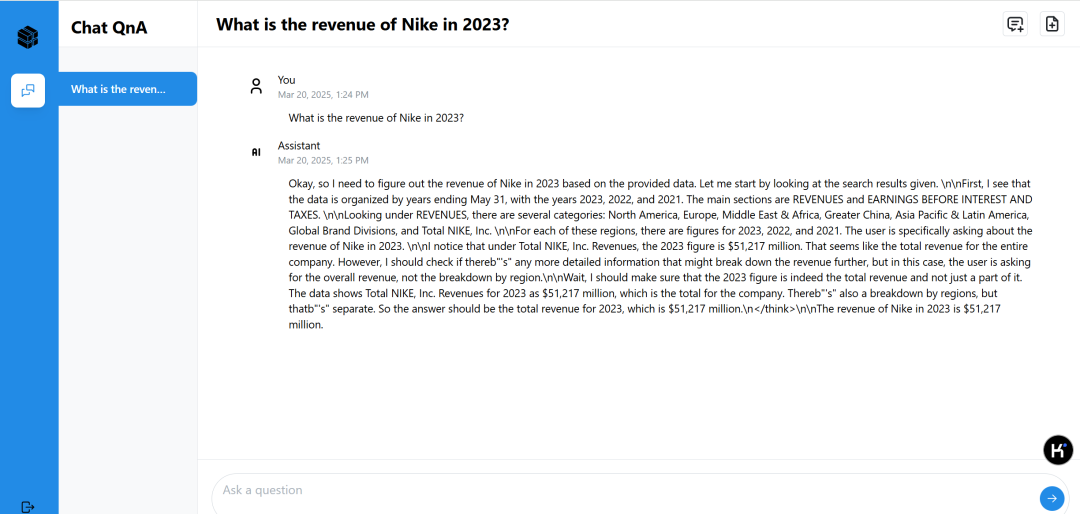
3.输入业务问题获取智能回复。
技术亮点
-
低成本部署:通过采用 4 路英特尔® 锐炫™ A770显卡,即可实现生产级服务的部署,大幅降低了硬件成本和资源消耗,为企业提供了一种经济高效的解决方案。
-
端到端流程:方案覆盖了从知识库准备到智能问答的完整闭环流程。用户无需额外开发或集成其他工具,即可快速搭建一套功能完善的智能问答系统。
-
企业级特性:确保企业敏感数据在本地进行处理,避免数据泄露风险,满足金融、制造等行业的高安全性要求。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐


 23
23 0
0- 0



 已为社区贡献221条内容
已为社区贡献221条内容

所有评论(0)