用GenAIEval工具做OPEA AI应用的性能评估
本篇文章主要目标是介绍性能评估部分,同时提供详细的步骤,让读者可以跟着一步一步搭建运行,对该工具有一个感性的认识。具体的分析方法及更多的深度内容,可以参考系列中其它的文章。
OPEA性能评估工具
OPEA开源社区除了提供多种具体AI应用的示例及一键部署方法外,也集成了完善的性能调优工具供开发者使用,方便开发企业级的应用。
GenAIEval项目(https://github.com/opea-project/GenAIEval)是平台的调优工具,它集成了两方面的功能,一是准确性的评估,包括答案回答是否准确,有没有幻觉(hallucination)等等;一是对于性能的评估,包括应用的延时,吞吐量等等。本篇文章主要目标是介绍性能评估部分,同时提供详细的步骤,让读者可以跟着一步一步搭建运行,对该工具有一个感性的认识。具体的分析方法及更多的深度内容,可以参考系列中其它的文章。
性能评估有什么用
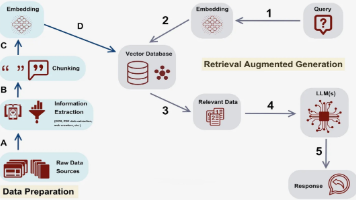
OPEA中的AI应用都是基于微服务架构的,多个独立的组件(GenAIComps)通过RestfulAPI接口互相调用,组成一个完整的应用(GenAIExamples)。企业级的部署一般都是在kubernetes云环境中,各种服务分布在不同的节点上,给观测、评估性能带来一定的挑战,管理员需要考虑如何合理分配资源以达到最佳性能或者最佳资源利用率等。拿ChatQnA作为例子,主要的服务有llm,embedding,reranking,向量数据库,检索器(retriever)等等,其中llm,embedding,reranking可以用GPU或者Gaudi等AI硬件来加速。在你的硬件资源有限的情况下,如何在这几个服务之间分配AI加速器就是一个需要慎重考虑的问题。
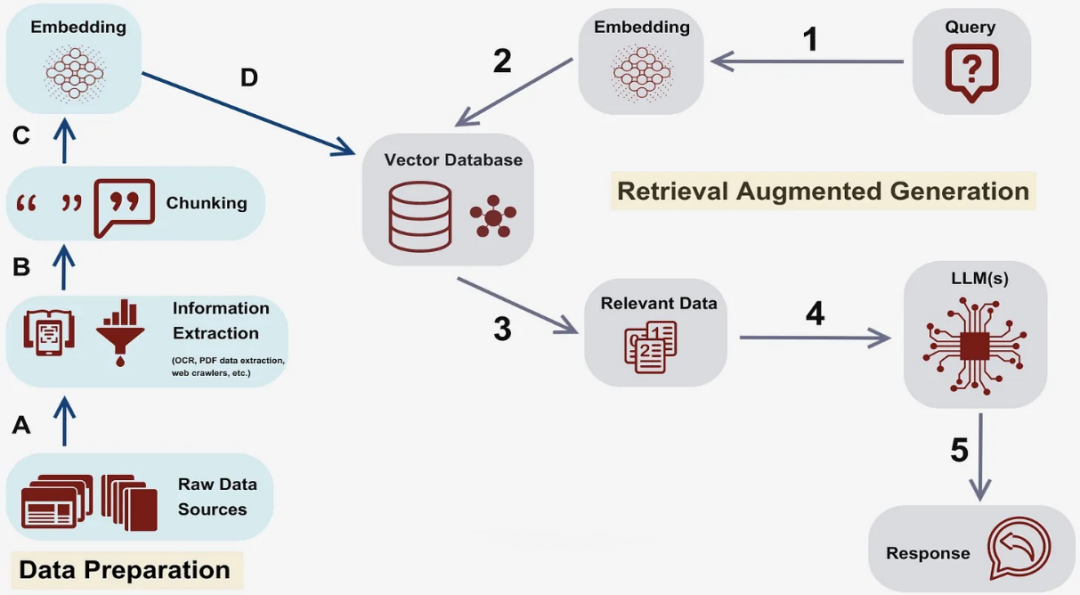
ChatQnA架构图
GenAIEval中的性能分析组件提供多角度的性能评估及数据收集来帮助用户完成这一工作。它支持端到端的测试和针对单独组件的测试,支持模拟多个用户,发送不同的负载,收集每个组件的性能数据以供分析。
接下来我们具体看看如何使用GenAIEval的benchmark工具来分析性能。
前提条件
确保你已经在单节点的环境用docker compose部署了ChatQnA。
参考https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/docker_compose/intel/cpu/xeon/README.md#quick-start-2run-docker-compose
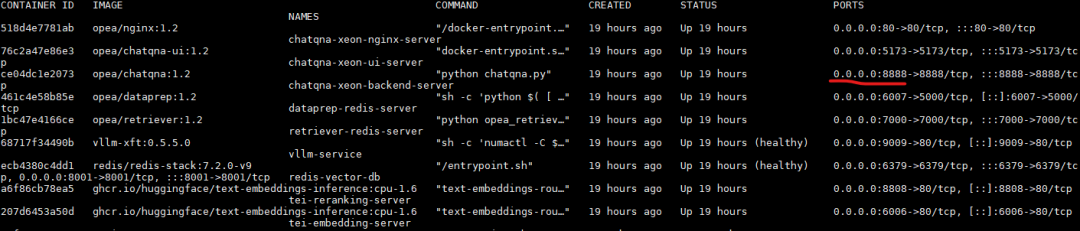
部署ChatQnA样例
准备benchmark环境
下载工具并安装依赖包,我们使用最新的稳定版1.2,并且创建一个virtualenv环境来运行我们的脚本。
# 下载代码仓库,并切换到1.2版git clone https://github.com/opea-project/GenAIEvalcd GenAIEvalgit checkout -b v1.2 origin/v1.2rc# 创建virtualenv环境,并安装依赖包virtualenv venvsource venv/bin/activatepip install -r requirements.txt # 安装项目依赖包pip install -r evals/benchmark/stresscli/requirements.txt #安装stresscli的依赖包cd evals/benchmark #进入到执行目录
修改配置文件benchmark.yaml
针对默认使用docker compose安装的ChatQnA,我们需要修改以下几项,更多的选项修改可以打开benchmark.yaml查看详细说明:
test_suite_config:deployment_type: "docker" #默认是k8s,需要改成dockerservice_ip: localhostservice_port: 8888 #指定chatqna的服务地址和端口,默认用localhost:8888user_queries: [64] #总共发送64个requestscollect_service_metric: true # 打开metrics收集功能llm_model: "../../../opea-chatqna/weights/DeepSeek-R1-Distill-Qwen-7B" # 下载的模型路径test_output_dir: "benchmark_output" #存放benchmark结果的目录load_shape:params:constant:concurrent_level: 16 #每个用户16个请求,所以是64/16=4个用户并发test_cases:chatqna:e2e:run_test: true #只打开e2e的测试service_name: "chatqna-xeon-backend-server" #按照上面docker ps的输出指定chatqna服务名称service_list: # 需要统计metrics的服务列表,这里我们统计几个主要的服务- "chatqna-xeon-backend-server"- "tei-embedding-server"- "vllm-service"- "tei-reranking-server"- "retriever-redis-server"
运行测试
在修改完配置文件后,只需要使用
python benchmark.py来运行。我们的配置一共发送64个请求,大概需要几分钟的时间即可完成。
查看结果
测试完成后,会在屏幕上打印出测试的日志以及日志存放的目录。

进入目录就可以看到详细的日志文件及统计信息。
cd benchmark_output/chatqnafixed_20250416_221317cat 1_metrics.json

从日志中可以看到详细的测试过程以及每个服务花的时间,可以根据这些数据来调整服务的副本,资源限制等等来达到理想的性能状态。

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐


 10
10 0
0- 0



 已为社区贡献221条内容
已为社区贡献221条内容

所有评论(0)