用 OpenVINO™ GenAI 解锁 LoRA 微调模型推理:高效定制你的大语言模型
通过将 LoRA 适配器与 OpenVINO™ GenAI 结合使用,你可以高效地将大型语言模型(LLM)适配到特定任务上,同时显著降低资源消耗。无论你是在开发 AI 聊天机器人、虚拟助手,还是内容生成工具,LoRA 都能为你提供一种灵活且强大的微调解决方案。
武卓
大语言模型(LLM)彻底改变了人类文本生成的方式,使其在聊天机器人、虚拟助手和内容生成等场景中变得不可或缺。然而,要将这些庞大的模型微调用于特定任务,通常需要大量的计算资源和训练时间。但如果你可以在不重新训练整个模型的情况下,高效地完成微调,会怎样?这正是 LoRA(低秩适配,Low-Rank Adaptation)大显身手的地方。
LoRA 通过引入一组小型可训练矩阵,为大模型提供了一种轻量级、低成本的定制方式,大幅降低了内存占用。现在,借助 OpenVINO™ GenAI,你可以无缝集成 LoRA适配器,实现对大语言模型的快速个性化定制。开发者还可以一次性加载多个 LoRA 适配器,并在运行时快速切换,无需重新编译基础模型。无论你是在构建智能客服机器人、生成个性化内容,还是自动化知识管理流程,OpenVINO 搭配 LoRA 适配器都能帮助你用更少的资源,实现更多可能。
接下来,我们一起来看看,使用 OpenVINO GenAI 运行 LoRA 适配器 进行 LLMs 推理,究竟有多简单!
目录
1. 克隆OpenVINO™ GenAI GitHub仓库
2. 为AI 模型转化安装依赖包
3. 下载和准备大语言模型及其LoRA适配器
4. 使用LoRA适配器运行LLM推理
5. 使用C++构建和运行带有LoRA的文本生成
6. 结论
步骤1: 克隆 OpenVINO™ GenAI GitHub仓库
要使用 OpenVINO GenAI API 实现推测式解码,首先需要克隆 openvino.genai GitHub 仓库。该仓库包含带有LoRA适配器的文本生成的示例实现,支持 Python 和 C++,可帮助开发者快速上手并部署高效的 LLM 推理方案。
git clone https://github.com/openvinotoolkit/openvino_genai.git
cd openvino_genai
步骤2: 为AI 模型转化安装依赖包(Python)
要运行 OpenVINO GenAI的带LoRA的LLM推理示例,需要配置环境并安装必要的工具、库和相关依赖项。请按照以下步骤正确安装所需组件。
1.创建 Python 虚拟环境
虚拟环境可以隔离项目依赖,确保一个干净、无冲突的开发环境。使用以下命令创建并激活虚拟环境:
python3 -m venv venv_export
source venv_export/bin/activate # For Windows: openvino_env\Scripts\activate2.安装必要的库
为了将模型导出为 OpenVINO 兼容格式,需要安装相关依赖项。运行以下命令安装必要的库:
pip install --upgrade-strategy eager -r ../../export-requirements.txt此命令确保所有必需的库都已安装并可正常使用,包括 OpenVINO GenAI、Hugging Face 工具 和 Optimum CLI。这些组件将支持带LoRA的LLM推理的实现,使开发者能够高效导出和优化模型,从而加速 LLM 推理过程。
步骤3: 下载和准备LLM及其LoRA适配器
对于文本生成,我们将使用 Llama-3.2-3B-Instruct 模型,该模型可以通过以下命令一键下载并转换为 OpenVINO™ IR 格式:
optimum-cli export openvino --model meta-llama/Llama-3.2-3B-Instruct --weight-format int4 --group-size 64 --ratio 1.0 Llama-3.2-3B-Instruct/INT4除此之外,还有其他支持 LoRA 适配器的大语言模型,完整列表见此页面,欢迎自由尝试。
稍等片刻后,模型将出现在本地磁盘上,可直接用于文本生成。如果后续不再需要进行模型转换或优化,可以将 venv_export 文件夹从磁盘中删除——这些依赖项并不是运行推理所必须的。
步骤4: 使用LoRA适配器运行LLM推理
首先,我建议你创建一个 Python 虚拟环境来运行 AI 推理。与用于模型下载和转换的环境不同,这里你只需要安装一个 Python 包 —— openvino.genai。
python -m venv venv
venv\Scripts\activate
pip install -r ../../deployment-requirements.txtopenvino_genai.AdapterConfig 用于在 openvino_genai.LLMPipeline 中管理 LoRA 适配器。你可以通过它添加或移除适配器,也可以调整它们的权重系数 alpha。Alpha 混合系数 是一个缩放因子,用于控制 LoRA 适配器在推理时对模型输出的影响程度。
- 较高的 alpha 值会增强适配器的影响力,适用于当前任务与基础模型的预训练任务差异较大时;
- 较低的 alpha 值则能弱化适配器的干预,更好地保留基础模型原有的行为特性。
你可以向配置中添加一个 LoRA 适配器,并为其设置特定的 alpha 值,以实现更加定制化的文本生成。
目前,OpenVINO™ GenAI 支持以 Safetensors 格式 保存的 LoRA 适配器。你可以选择 Hugging Face Hub 上公开的预训练适配器,或自行训练适配器。
那怎么为某个 LLM 模型找到开源的 LoRA 适配器呢?其实很简单:
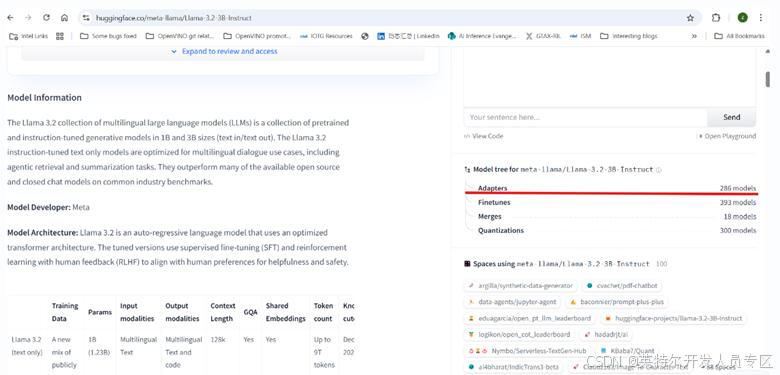
以 Llama-3.2–3B-Instruct 为例,打开该模型的 Hugging Face “Model card” 页面,向下滚动页面,在右侧会看到名为 “Model tree” 的模块,如下图所示。其中的第一个部分就是 “Adapters”。
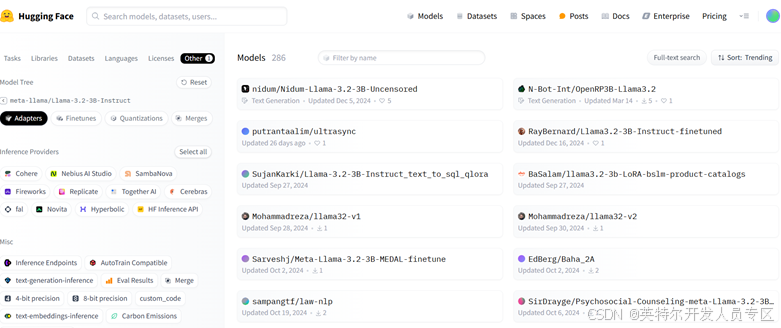
点击该链接后,你将跳转到 Hugging Face 上该模型所有开源 LoRA 适配器的列表页面(如下图所示)。在这里,你可以点击每个 LoRA 适配器的链接,选择最适合你应用场景的那个版本。
处理 LoRA 适配器的代码示例如下:
adapter = openvino_genai.Adapter(args.adapter_path)
adapter_config = openvino_genai.AdapterConfig(adapter)将 LoRA 集成进 GenAI API 的文本生成推理流程中只需一行代码:
pipe = openvino_genai.LLMPipeline(args.models_path, device, adapters=adapter_config) # register all required adapters here在本文中,我们选择了适用于 Llama-3.2–3B-Instruct 的 LoRA 适配器。使用如下命令,即可调用 “bosmet/lora_model_llama-3.2–3B-Instruct” LoRA 适配器和 INT4 量化的 Llama-3.2–3B-Instruct 模型来生成文本:
python lora_greedy_causal_lm.py./Llama-3.2-3B-Instruct/INT4 adapter_model.safetensors prompt请注意,在加载预训练适配器之前,务必确保其与基础模型架构兼容。例如,如果你使用的是 Llama-3.2–3B-Instruct 模型,那么必须选择为该模型类型训练的 LoRA 适配器。否则,如果适配器是为其他类型的 LLM 模型训练的,将无法在推理流程中正确集成与运行。
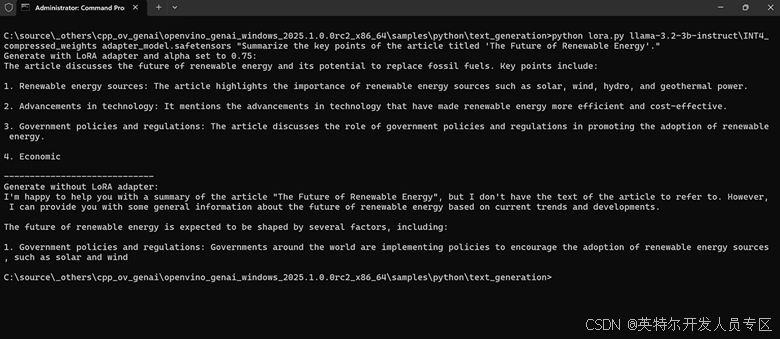
步骤5:使用C++构建和运行带有LoRA的文本生成
尽管 Python 是一门功能强大的编程语言,非常适合进行代码实验,但在很多情况下,C++ 更常用于桌面应用程序的开发。下面是一个使用 LoRA 进行文本生成的 C++ 示例代码:
大语言模型(LLM)彻底改变了人类文本生成的方式,使其在聊天机器人、虚拟助手和内容生成等场景中变得不可或缺。然而,要将这些庞大的模型微调用于特定任务,通常需要大量的计算资源和训练时间。但如果你可以在不重新训练整个模型的情况下,高效地完成微调,会怎样?这正是 LoRA(低秩适配,Low-Rank Adaptation)大显身手的地方。
LoRA 通过引入一组小型可训练矩阵,为大模型提供了一种轻量级、低成本的定制方式,大幅降低了内存占用。现在,借助 OpenVINO™ GenAI,你可以无缝集成 LoRA适配器,实现对大语言模型的快速个性化定制。开发者还可以一次性加载多个 LoRA 适配器,并在运行时快速切换,无需重新编译基础模型。无论你是在构建智能客服机器人、生成个性化内容,还是自动化知识管理流程,OpenVINO 搭配 LoRA 适配器都能帮助你用更少的资源,实现更多可能。
std::string device = "CPU"; // GPU can be used as well
using namespace ov::genai;
Adapter adapter(adapter_path);
LLMPipeline pipe(models_path, device, adapters(adapter)); // register all required adapters here
// Resetting config to set greedy behaviour ignoring generation config from model directory.
// It helps to compare two generations with and without LoRA adapter.
ov::genai::GenerationConfig config;
config.max_new_tokens = 100;
pipe.set_generation_config(config);
std::cout << "Generate with LoRA adapter and alpha set to 0.75:" << std::endl;
std::cout << pipe.generate(prompt, max_new_tokens(100), adapters(adapter, 0.75)) << std::endl;
std::cout << "\n-----------------------------";
std::cout << "\nGenerate without LoRA adapter:" << std::endl;
std::cout << pipe.generate(prompt, max_new_tokens(100), adapters()) << std::endl;
有关使用 LoRA 构建文本生成图像的 C++ 应用程序所需内容的详细指南,请参考此处。
用 OpenVINO GenAI 解锁 LoRA 微调模型
结论:
通过将 LoRA 适配器与 OpenVINO™ GenAI 结合使用,你可以高效地将大型语言模型(LLM)适配到特定任务上,同时显著降低资源消耗。无论你是在开发 AI 聊天机器人、虚拟助手,还是内容生成工具,LoRA 都能为你提供一种灵活且强大的微调解决方案。
欢迎深入探索 OpenVINO GenAI API,尝试集成多种 LoRA 适配器,全面提升你的 AI 应用能力。
祝编码愉快!

为开发者提供丰富的英特尔开发套件资源、创新技术、解决方案与行业活动。欢迎关注!
更多推荐


 9
9 0
0- 0



 已为社区贡献221条内容
已为社区贡献221条内容

所有评论(0)